I recently downloaded the stackoverflow.com-Posts.7z file from the 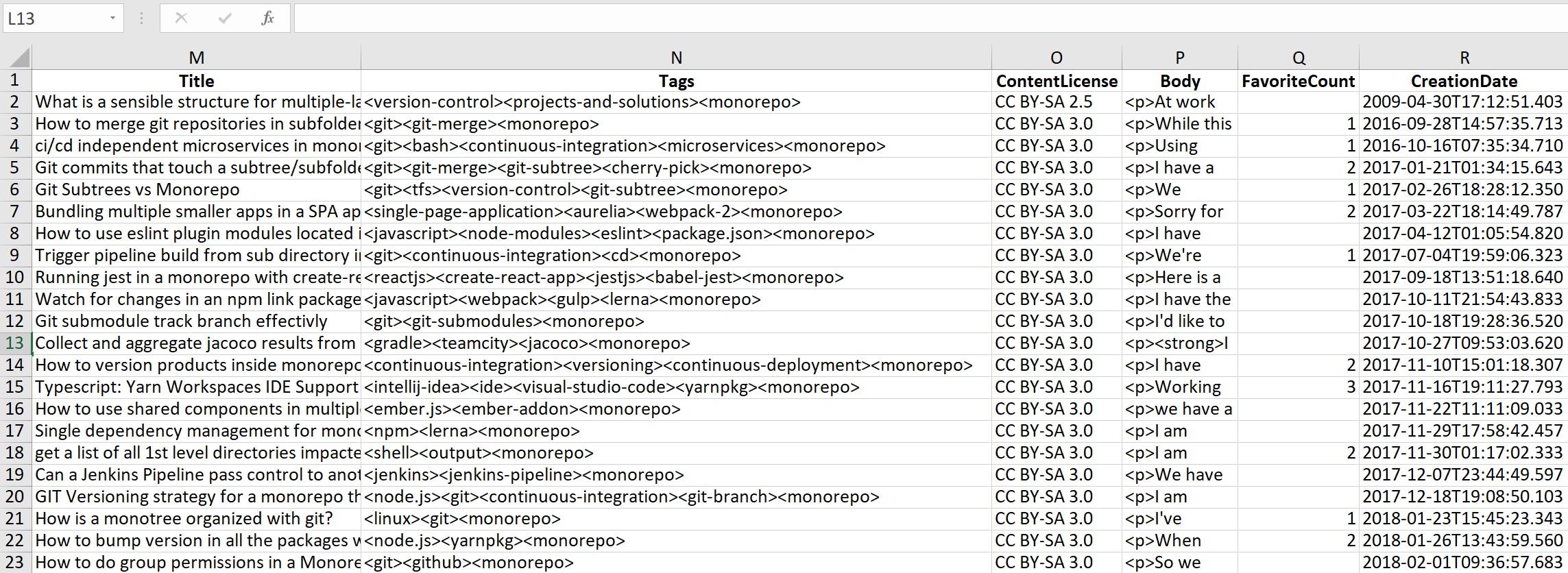
My issue is that I am trying to count the frequency of only particular tags of interest from the Posts.csv file, given a list, in Python. For example, suppose I have the following list in Python:
tagsOfInterest = ['version-control', 'git', 'git-merge', 'bash', 'microservices']
Only in the Tags column of the CSV file, I would like to count how many times the tag version-control appears, how many times the tag git appears, how many times the tag git-merge appears, etc...
I've been struggling to do this because you'll notice that each row in the Tags column is formatted as a continuous string, with each different tag word only separated by a <>. For instance, in the first row, a post has been tagged with <version-control><projects-and-solutions><monorepo>.
My original attempt involved first reading the Posts.csv file, and then adding each row in the Tags column to a list, as such:
from pandas import *
import csv
# Read data
data = read_csv("Posts.csv")
# Add each row in the "Tags" column to a list:
tags_col = data['Tags'].tolist()
and then my idea was to just tokenize each tag word. However, the Posts.csv file is so large, that my computer runs out of memory just from creating the list!
As such, my question is: given a list of tags that are of interest, e.g., tagsOfInterest = ['version-control', 'git', 'git-merge', 'bash', 'microservices'], how can I count the frequency of each element in that list, from the Tags column of the Posts.CSV file?
CodePudding user response:
import csv
from collections import Counter
counts = Counter()
for row in csv.reader(open('Posts.csv')):
for tag in row[1].lstrip('<').rstrip('>').split('<>'):
counts[tag] = 1
print(counts)
You can use a DictReader if you want, to use row['Tags'] instead of row[1].