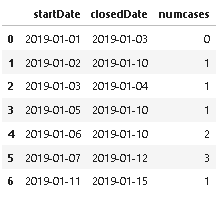
I have a dataframe of start date and closed date of cases. I want to do a count of how many cases are available at the start of each case.
caseNo startDate closedDate
1 2019-01-01 2019-01-03
2 2019-01-02 2019-01-10
3 2019-01-03 2019-01-04
4 2019-01-05 2019-01-10
5 2019-01-06 2019-01-10
6 2019-01-07 2019-01-12
7 2019-01-11 2019-01-15
Output will be:
caseNo startDate closedDate numCases
1 2019-01-01 2019-01-03 0
2 2019-01-02 2019-01-10 1
3 2019-01-03 2019-01-04 1
4 2019-01-05 2019-01-10 1
5 2019-01-06 2019-01-10 2
6 2019-01-07 2019-01-12 3
7 2019-01-11 2019-01-15 1
For example, for case 6, cases 2,4,5 still have not been closed. So there are 3 cases outstanding. Also, the dates are actually datetimes rather than just date. I have only included the date here for brevity.
CodePudding user response:
Solution in numba should increase performance (best test in real data):
from numba import jit
@jit(nopython=True)
def nb_func(x, y):
res = np.empty(x.size, dtype=np.int64)
for i in range(x.size):
res[i] = np.sum(x[:i] > y[i])
return res
df['case'] = nb_func(df['closedDate'].to_numpy(), df['startDate'].to_numpy())
print (df)
caseNo startDate closedDate case
0 1 2019-01-01 2019-01-03 0
1 2 2019-01-02 2019-01-10 1
2 3 2019-01-03 2019-01-04 1
3 4 2019-01-05 2019-01-10 1
4 5 2019-01-06 2019-01-10 2
5 6 2019-01-07 2019-01-12 3
6 7 2019-01-11 2019-01-15 1
CodePudding user response:
Use:
res = []
temp = pd.to_datetime(df['closedDate'])
for i, row in df.iterrows():
temp_res = np.sum(row['startDate']<temp.iloc[:i])
print(temp_res)
res.append(temp_res)
output:
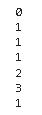
Then you can add the result as a df column: