I am trying to load a complex JSON file (multiple different data types, nested objects/arrays etc) from my local, read them in as a source using the 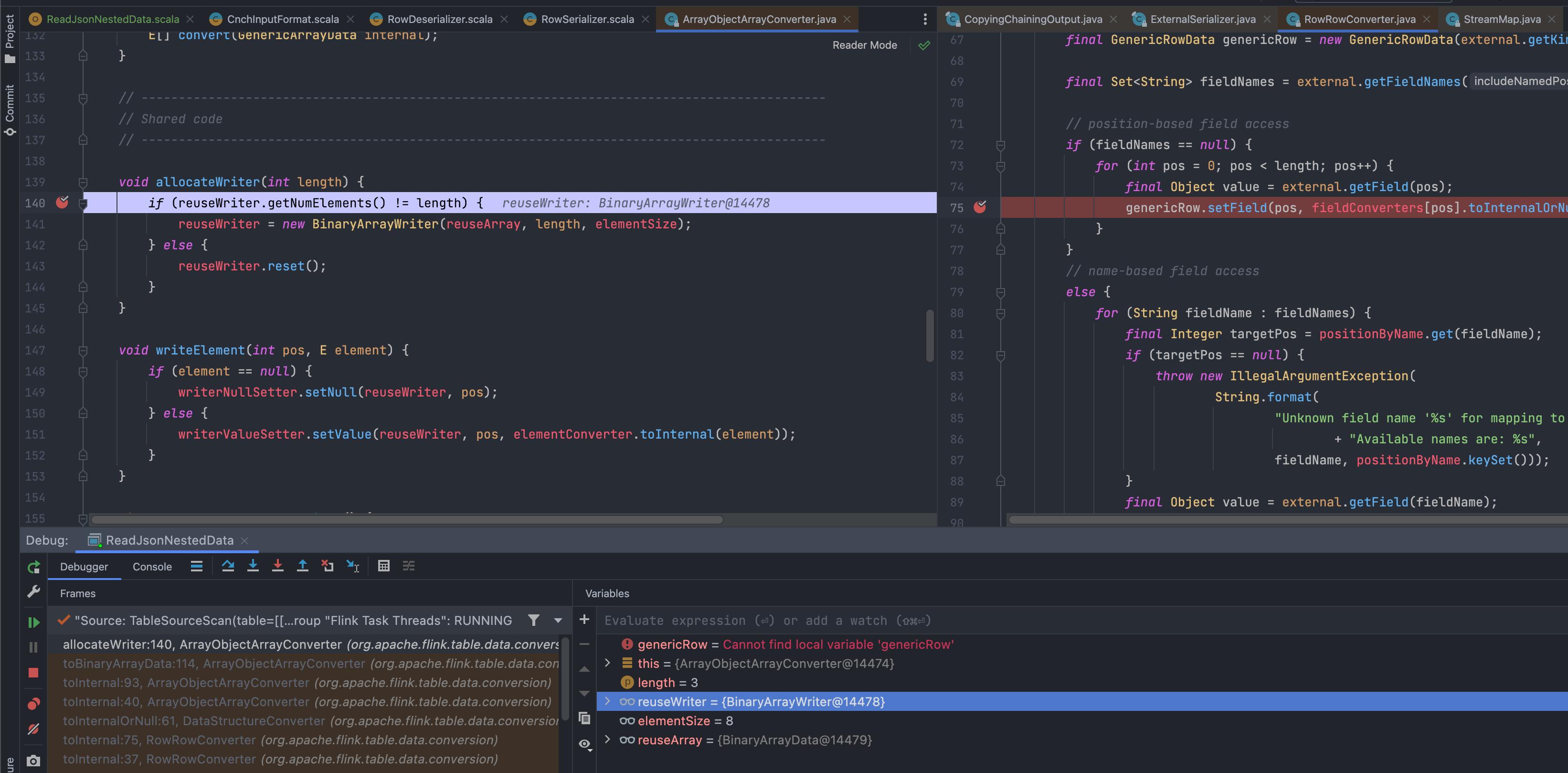
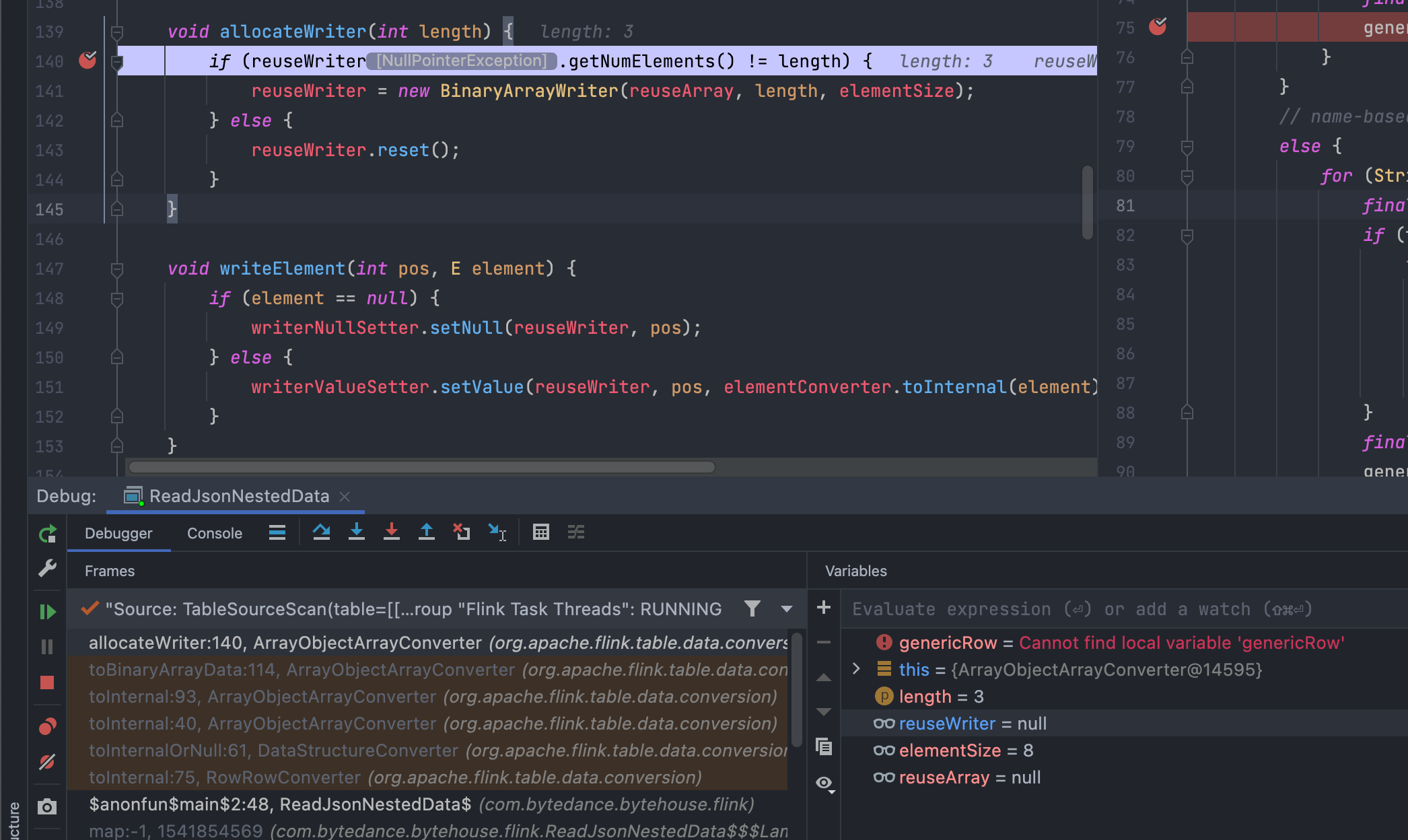
However, for some strange reason, RowRowConverter::toInternal runs twice, and if I continue stepping through eventually it will come back here, which is where the null pointer exception happens.
Example of the JSON (simplified with only a single nested for brevity). I placed it in my /src/main/resources folder
{"discount":[670237.997082,634079.372133,303534.821218]}
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment
import org.apache.flink.table.data.conversion.RowRowConverter
import org.apache.flink.table.types.FieldsDataType
import org.apache.flink.table.types.logical.RowType
import scala.collection.JavaConverters._
object ReadJsonNestedData {
def main(args: Array[String]): Unit = {
// setup
val jsonResource = getClass.getResource("/NESTED.json")
val jsonFilePath = jsonResource.getPath
val tableName = "orders"
val readJSONTable =
s"""
| CREATE TABLE $tableName (
| `discount` ARRAY<DECIMAL(12, 6)>
| )WITH (
| 'connector' = 'filesystem',
| 'path' = '$jsonFilePath',
| 'format' = 'json'
|)""".stripMargin
val colFields = Array(
"discount"
)
val defaultDataTypes = Array(
DataTypes.ARRAY(DataTypes.DECIMAL(12, 6))
)
val rowType = RowType.of(defaultDataTypes.map(_.getLogicalType), colFields)
val defaultDataTypesAsList = defaultDataTypes.toList.asJava
val dataType = new FieldsDataType(rowType, defaultDataTypesAsList)
val rowConverter = RowRowConverter.create(dataType)
// Job
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val tableEnv = StreamTableEnvironment.create(env)
tableEnv.executeSql(readJSONTable)
val ordersTable = tableEnv.from(tableName)
val dataStream = tableEnv
.toDataStream(ordersTable)
.map(row => rowConverter.toInternal(row))
dataStream.print()
env.execute()
}
}
I would hence like to know:
- Why
RowRowConverteris not working and how I can remedy it - Why
RowRowConverter::toInternalis running twice for the sameRow.. which may be the cause of thatNullPointerException - If my method of instantiating and using the
RowRowConverteris correct based on my code above.
Thank you!
Environment:
- IntelliJ 2021.3.2 (Ultimate)
- AdoptOpenJDK
1.8 - Scala:
2.12.15 - Flink:
1.13.5 - Flink Libraries Used (for this example):
flink-table-api-java-bridgeflink-table-planner-blinkflink-clientsflink-json
CodePudding user response:
The first call of RowRowConverter::toInternal is an internal implementation for making a deep copy of the StreamRecord emitted by table source, which is independent from the converter in your map function. The reason of the NPE is that the RowRowConverter in the map function is not initialized by calling RowRowConverter::open. You can use RichMapFunction instead to invoke the RowRowConverter::open in RichMapFunction::open.
CodePudding user response:
Thank you to @renqs for the answer.
Here is the code, if anyone is interested.
class ConvertRowToRowDataMapFunction(fieldsDataType: FieldsDataType)
extends RichMapFunction[Row, RowData] {
private final val rowRowConverter = RowRowConverter.create(fieldsDataType)
override def open(parameters: Configuration): Unit = {
super.open(parameters)
rowRowConverter.open(this.getClass.getClassLoader)
}
override def map(row: Row): RowData =
this.rowRowConverter.toInternal(row)
}
// at main function
// ... continue from previous
val dataStream = tableEnv
.toDataStream(personsTable)
.map(new ConvertRowToRowDataMapFunction(dataType))