How can I only get the data with the same ID, but not the same Name?
The following is the example to explain my thought. Thanks.
ID Name Date
123 Amy 08/03/2022
123 Amy 12/03/2022
456 Billy 08/03/2022
456 Cat 09/03/2022
789 Peter 10/03/2022
Expected Output:
ID Name Date
456 Billy 08/03/2022
456 Cat 09/03/2022
How I have done.
select ID, Name, count(*)
from table
groupby ID, Name
having count(*) > 1
But the result included the following parts that I do not want it.
ID Name Date
123 Amy 08/03/2022
123 Amy 12/03/2022
CodePudding user response:
One approach would be to use a subquery to identify IDs that have multiple names.
SELECT *
FROM YourTable
WHERE ID IN (SELECT ID FROM YourTable GROUP BY ID HAVING COUNT(DISTINCT Name) > 1)
CodePudding user response:
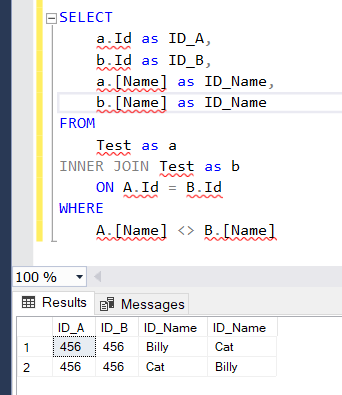
I'd join the table to its self like this:
SELECT DISTINCT
a.Id as ID_A,
b.Id as ID_B,
a.[Name] as Name_A
FROM
Test as a
INNER JOIN Test as b
ON A.Id = B.Id
WHERE
A.[Name] <> B.[Name]
CodePudding user response:
Do you want
SELECT * FROM table_name
WHERE ID = 456;
or
SELECT * FROM table_name
WHERE ID IN
(SELECT
ID
FROM table_name
GROUP BY ID
HAVING COUNT(DISTINCT name) > 1
);
?
CodePudding user response:
Window functions are likely to be the most efficient here. They do not require self-joining of the source table.
Unfortunately, SQL Server does not support COUNT(DISTINCT as a window function. But we can simulate it by using DENSE_RANK and MAX
WITH DistinctRanks AS (
SELECT *,
rnk = DENSE_RANK(*) OVER (PARTITION BY ID ORDER BY Name)
FROM YourTable
),
MaxRanks AS (
SELECT *,
mr = MAX(rnk) OVER (PARTITION BY ID)
FROM DistinctRanks
)
SELECT
ID,
Name,
Count
FROM MaxRanks t
WHERE t.mr > 1;