I have this dataframe:
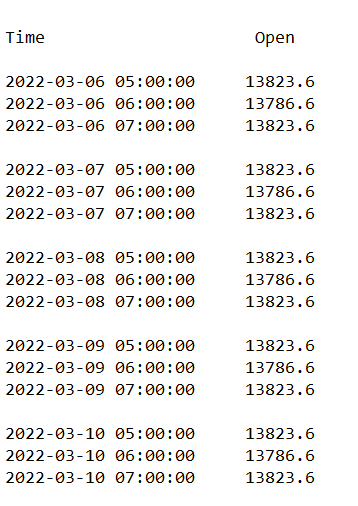
I need to get the values of the single days between time 05:00:00 and 06:00:00 (so, in this example, ignore 07:00:00) And create a separate dataframe for each day considering the last 3 days.
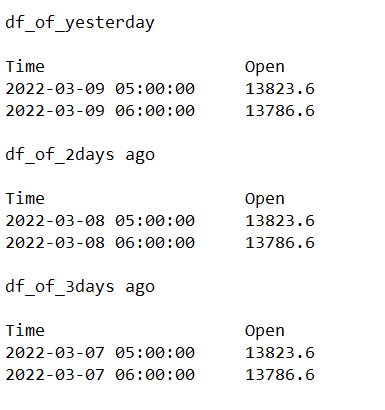
This is the result i want to achive: (3 dataframes considering 3 days and Time between 05 and 06)
I tried this: (without success)
df.sort_values(by = "Time", inplace=True)
df_of_yesterday = df[ (df.Time.dt.hour > 4)
& (df.Time.dt.hour < 7)]
CodePudding user response:
You can use:
from datetime import date, time, timedelta
today = date.today()
m = df['Time'].dt.time.between(time(5), time(6))
df_yda = df.loc[m & (df['Time'].dt.date == today - timedelta(1))]
df_2da = df.loc[m & (df['Time'].dt.date == today - timedelta(2))]
df_3da = df.loc[m & (df['Time'].dt.date == today - timedelta(3))]
Output:
>>> df_yda
Time Open
77 2022-03-09 05:00:00 0.880443
78 2022-03-09 06:00:00 0.401932
>> df_2da
Time Open
53 2022-03-08 05:00:00 0.781377
54 2022-03-08 06:00:00 0.638676
>>> df_3da
Time Open
29 2022-03-07 05:00:00 0.838719
30 2022-03-07 06:00:00 0.897211
Setup a MRE:
import pandas as pd
import numpy as np
rng = np.random.default_rng()
dti = pd.date_range('2022-03-06', '2022-03-10', freq='H')
df = pd.DataFrame({'Time': dti, 'Open': rng.random(len(dti))})
CodePudding user response:
Use Series.between with set offsets.DateOffset for datetimes between this times in list comprehension for list of DataFrames:
now = pd.to_datetime('now').normalize()
dfs = [df[df.Time.between(now - pd.DateOffset(days=i, hour=5),
now - pd.DateOffset(days=i, hour=6))] for i in range(1,4)]
print (dfs[0])
print (dfs[1])
print (dfs[2])
CodePudding user response:
I've manually copied your data into a dictionary and then converted it to your desired output.
First you should probably edit your question to use the text version of the data instead of an image, here's a small example:
data = {
'Time': [
'2022-03-06 05:00:00',
'2022-03-06 06:00:00',
'2022-03-06 07:00:00',
'2022-03-07 05:00:00',
'2022-03-07 06:00:00',
'2022-03-07 07:00:00',
'2022-03-08 05:00:00',
'2022-03-08 06:00:00',
'2022-03-08 07:00:00',
'2022-03-09 05:00:00',
'2022-03-09 06:00:00',
'2022-03-09 07:00:00'
],
'Open': [
'13823.6',
'13786.6',
'13823.6',
'13823.6',
'13786.6',
'13823.6',
'13823.6',
'13786.6',
'13823.6',
'13823.6',
'13786.6',
'13823.6'
]
}
df = pd.DataFrame(data)
Then you can use this code to get all the dates that are on the same day and in between the hours 4 and 7 and then create your dataframes as follows:
import pandas as pd
from datetime import datetime
dict = {}
for index, row in df.iterrows():
found = False
for item in dict:
date = datetime.strptime(row['Time'], '%Y-%m-%d %H:%M:%S')
date2 = datetime.strptime(item, '%Y-%m-%d')
if(date.date() == date2.date() and date.hour > 4 and date.hour < 7):
dict[item].append(row['Open'])
found = True
date = datetime.strptime(row['Time'], '%Y-%m-%d %H:%M:%S')
if(not found and date.hour > 4 and date.hour < 7):
dict[date.strftime('%Y-%m-%d')] = []
dict[date.strftime('%Y-%m-%d')].append(row['Open'])
for key in dict:
temp = {
key: dict[key]
}
df = pd.DataFrame(temp)
print(df)