I'm quite new to data analysis (and Python in general), and I'm currently a bit stuck in my project.
For my NLP-task I need to create training data, i.e. find specific entities in sentences and label them. I have multiple csv files containing the entities I am trying to find, many of them consisting of multiple words. I have tokenized and lemmatized the unlabeled sentences with spaCy and loaded them into a pandas.DataFrame.
My main problem is: how do I now compare the tokenized sentences with the entity-lists and label the (often multi-word) entities? Having around 0.5 GB of sentences, I don't think it is feasible to just for-loop every sentence and then for-loop every entity in every class-list and do a simple substring-search. Is there any smart way to use pandas.Series or DataFrame to do this labeling?
As mentioned, I don't really have any experience regarding pandas/numpy etc. and after a lot of web searching I still haven't seemed to find the answer to my problem
Say that this is a sample of finance.csv, one of my entity lists:
"Frontwave Credit Union",
"St. Mary's Bank",
"Center for Financial Services Innovation",
...
And that this is a sample of sport.csv, another one of my entity lists:
"Christiano Ronaldo",
"Lewis Hamilton",
...
And an example (dumb) sentence:
"Dear members of Frontwave Credit Union, any credit demanded by Lewis Hamilton is invalid, said Ronaldo"
The result I'd like would be something like a table of tokens with the matching entity labels (with IOB labeling):
"Dear "- O
"members" - O
"of" - O
"Frontwave" - B-FINANCE
"Credit" - I-FINANCE
"Union" - I-FINANCE
"," - O
"any" - O
...
"Lewis" - B-SPORT
"Hamilton" - I-SPORT
...
"said" - O
"Ronaldo" - O
CodePudding user response:
Use:
import pandas as pd
df = pd.DataFrame({'tokens':[['a', 'sample'], ['another', 'sample'], ['a', 'good', 'sample']]})
entities = ['another', 'good', 'a']
ents = '|'.join(entities)
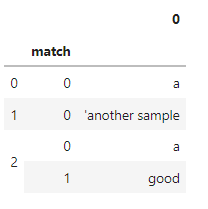
df['tokens'].astype(str).str.extractall(f"('{ents})'")
Output:
for multi-word tokens:
import pandas as pd
df = pd.DataFrame({'tokens':[['a', 'sample'], ['another sample', 'other token'], ['a', 'good', 'sample']]})
entities = ['another sample', 'good', 'a']
ents = '|'.join(entities)
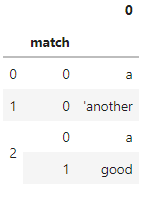
df['tokens'].astype(str).str.extractall(f"('{ents})'")
Output: