I have a dataframe of repetaed measures in WIDE format, with an ID variable (pid) some non time-varyant variables (i.e. age and sex) and mostly time-varyant variables, all named similarly with the following scheme: spec_var_0 spec_var_1 and spec_var_2 (we have 3 timewaves). Here it is an example:
structure(list(pid = structure(1:6, .Label = c("1", "2", "3",
"4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15",
"16", "17", "18", "19", "20"), class = "factor"), dem_age = c(50,
73, 55, 66, 65, 70), dem_sex = structure(c(1L, 2L, 1L, 2L, 2L,
2L), .Label = c("Female", "Male"), class = "factor"), hx_steatosis = structure(c(1L,
1L, 1L, 1L, 1L, 1L), .Label = c("No", "Yes"), class = "factor"),
bio_weight_0 = c(89.4, 73.9, 78.7, 86.2, 132, 90.5), bio_weight_1 = c(94.9,
66, 75.2, 82, 119, 81.6315789473684), bio_weight_2 = c(92,
56, 71, 81, 118, 86.5), lab_glyc_0 = c(5.52545293913178,
4.88280192258637, 4.79579054559674, 4.94875989037817, 5.17614973257383,
5.0998664278242), lab_glyc_1 = c(5.08140436498446, 5.01063529409626,
5.01727983681492, 4.77912349311153, 4.95582705760126, 5.03695260241363
), lab_glyc_2 = c(4.39444915467244, 5.06890420222023, 4.52178857704904,
4.62497281328427, 5.34710753071747, 4.95582705760126)), row.names = c(NA,
6L), class = "data.frame")
Now I would like to convert to pivot_longer so to have the following format (sorry for the image, I do not know how to build such a table in R)
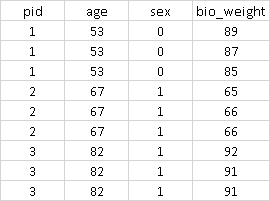
Searching Stack and other forums it seems that the issue could be fixed using refular expressions,but I have no idea of how to use them (in general and in this context specifically).
Any help would be (as usual) greatly appreciated
CodePudding user response:
I haven't quite taken you at your word as I have kept the number associated with the bio_weight in a column called bio_weight_num. But if you truly do not want it, you can just drop that column:
library(tidyr)
library(dplyr)
df %>%
select(-c(hx_steatosis, starts_with("lab_glyc"))) %>%
pivot_longer(
cols = starts_with("bio_weight"),
names_to = "bio_weight_num",
values_to = "bio_weight"
) %>%
mutate(
bio_weight_num = gsub("\\D", "", bio_weight_num)
)
# A tibble: 18 x 5
# pid dem_age dem_sex bio_weight_num bio_weight
# <fct> <dbl> <fct> <chr> <dbl>
# 1 1 50 Female 0 89.4
# 2 1 50 Female 1 94.9
# 3 1 50 Female 2 92
# 4 2 73 Male 0 73.9
# 5 2 73 Male 1 66
# 6 2 73 Male 2 56
# 7 3 55 Female 0 78.7
# 8 3 55 Female 1 75.2
# 9 3 55 Female 2 71
# 10 4 66 Male 0 86.2
# 11 4 66 Male 1 82
# 12 4 66 Male 2 81
# 13 5 65 Male 0 132
# 14 5 65 Male 1 119
# 15 5 65 Male 2 118
# 16 6 70 Male 0 90.5
# 17 6 70 Male 1 81.6
# 18 6 70 Male 2 86.5
I would suggest reading: https://tidyr.tidyverse.org/reference/pivot_longer.html
CodePudding user response:
Ok,
In this specific case (and not knowing Regular Expressions) I ended up renaming all variables in the dataframe to have a consistent but slightly different names structure: from spec_var_time to spec_var.time --> bio_weight_0 to bio_weight.0. This was useful in order to use names_sep option in pivot_longer. The following code works as expected:
testdf.l <- pivot_longer(data = testdf,
cols = c("bio_weight.0", "bio_weight.1", "bio_weight.2",
"lab_glyc.0", "lab_glyc.1", "lab_glyc.2"),
names_to = c('.value', 'timewave'),
names_sep = '\\.')
Again, thanks to SamR for the hints, and for having pointed me in the right direction