I am new to Redshift. I have two tables, ticket_booking and ticket_review, the relation of the two tables is one - many. Which when combined looks like:
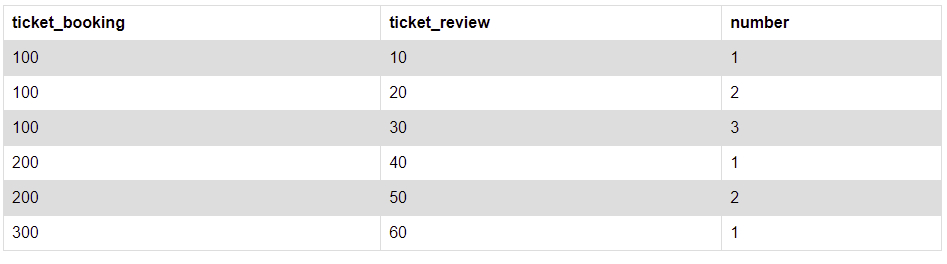
The result I am looking for (I want to get the highest number per ticket_booking id) is:

I tried to obtain the desired result using the group by command to help distinct records. See script below:
select b.id, r.id, max(r.number) as revision_number
from dw.ticket_review as r, dw.ticket_booking as b
where r.ticket_booking_id = b.id
group by b.id
However, I get an error column "r.id" must appear in the GROUP BY clause or be used in an aggregate function. If I do this I get the result of the first picture. I tried different approaches mentioned in different questions but none seem to help me with my situation. Any help would be deeply appreciated! :)
CodePudding user response:
Per booking assign row number ordering from highest review, then pick first rows only:
select booking_id, ticket_review, number
from (select b.id as booking_id, r.id as ticket_review, r.number,
row_number() over (partition by b.id order by r.id desc) rn
from dw.ticket_review as r, dw.ticket_booking as b
where r.ticket_booking_id = b.id) x
where rn = 1;