I have 2 tables with a large number of columns (each has around 700-800 columns, which makes it not feasible to individually write all the column names). Both the tables have a few common rows. I need to dynamically union both the tables such that the common columns don't get repeated and are queried only once in the final table. For example:
TABLE 1:
--------- -------- ------ -------
|firstname|lastname|upload|product|
--------- -------- ------ -------
| alice| a| 100|apple |
| bob| b| 23|orange |
--------- -------- ------ -------
TABLE 2:
--------- -------- ------ -------
|firstname|lastname|books |active |
--------- -------- ------ -------
| alice| a| 10 |yes |
| bob| b| 2 |no |
--------- -------- ------ -------
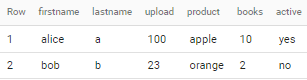
FINAL TABLE:
--------- -------- ------ ------- ----- ------
|firstname|lastname|upload|product|books|active|
--------- -------- ------ ------- ----- ------
| alice| a| 100|apple | 10 | yes |
| bob| b| 23|orange | 2 | no |
--------- -------- ------ ------- ----- ------
CodePudding user response:
Just to give you a direction to look into
select *
from table1
join table2
using(firstname, lastname)
if applied to sample data in your question - output is