Is there a way of joining two dataframes via where a row in the first dataframe is joined with every row in the second dataframe if they share a word in common?
For example:
companies1 <- data.frame(company_name = c("Walmart", "Amazon", "Apple", "CVS Health", "UnitedHealth Group", "Berkshire Hathaway", "Alphabet"))
companies2 <- data.frame(company_name = "Walmart Stores", "Walmart Inc", "Amazon Web Services", "Amazon Alexa", "Apple", "Apple Products", "CVS Health", "UnitedHealth Group", "Berkshire Hathaway", "Berkshire Hathaway Asset Management", "Meta"))
I'd like to match these so every single possible match between the left and right column is then returned, as below:
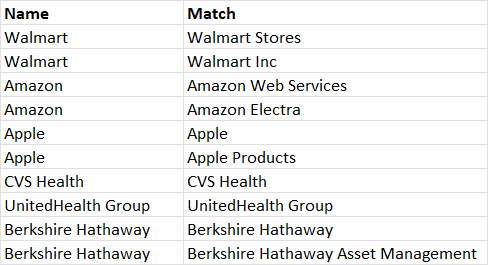
I've tried packages like fuzzymatch and stringdist, but for matching these seem to return the best match only. However, as the matching I'm doing isn't as neat as the above and is much bigger, my plan is to find possible matches, then give them a distance score (e.g. using Jaro-Winkler distance), at which point I'll have to manually select the right match (if any).
CodePudding user response:
With fuzzy_join:
library(fuzzyjoin)
fuzzy_join(companies2, companies1, match_fun = stringr::str_detect)
company_name.x company_name.y
1 Walmart Stores Walmart
2 Walmart Inc Walmart
3 Amazon Web Services Amazon
4 Amazon Alexa Amazon
5 Apple Apple
6 Apple Products Apple
7 CVS Health CVS Health
8 UnitedHealth Group UnitedHealth Group
9 Berkshire Hathaway Berkshire Hathaway
10 Berkshire Hathaway Asset Management Berkshire Hathaway
Or, if you want to respect the order of the columns:
fuzzy_join(companies1, companies2, match_fun = function(x, y) stringr::str_detect(y, x))
company_name.x company_name.y
1 Walmart Walmart Stores
2 Walmart Walmart Inc
3 Amazon Amazon Web Services
4 Amazon Amazon Alexa
5 Apple Apple
6 Apple Apple Products
7 CVS Health CVS Health
8 UnitedHealth Group UnitedHealth Group
9 Berkshire Hathaway Berkshire Hathaway
10 Berkshire Hathaway Berkshire Hathaway Asset Management