Do you have any idea how to read PDF files, which mimetype is text/html?
I have tried the snippet below, but OCR doesn't work, resulting in this issue "API call to drive.files.insert failed with error: OCR is not supported for files of type text/html"
function extractTextFromPDF(pdfID) {
// PDF File URL
// You can also pull PDFs from Google Drive
var url = "https://drive.google.com/file/d/" pdfID
var blob = UrlFetchApp.fetch(url).getBlob();
var resource = {
title: blob.getName(),
mimeType: blob.getContentType(),
};
// Enable the Advanced Drive API Service
var file = Drive.Files.insert(resource, blob, { ocr: true, ocrLanguage: 'en' });
// Extract Text from PDF file
var doc = DocumentApp.openById(file.id);
var text = doc.getBody().getText();
return text;
}
Also, I have tried to convert files to any other format like .csv .css or text, but when did it the text is horrible, long HTML, with content encrypted I think. I considered splitting data from extracted HTML, but unfortunately, content is not there or is encrypted somehow.
What I want to do is to print the text from this wired pdf, so I can later write it to Google Sheets. Do you have any idea how I can read this file?
File
I am attaching a pdf here, so you can see what I am fighting with.
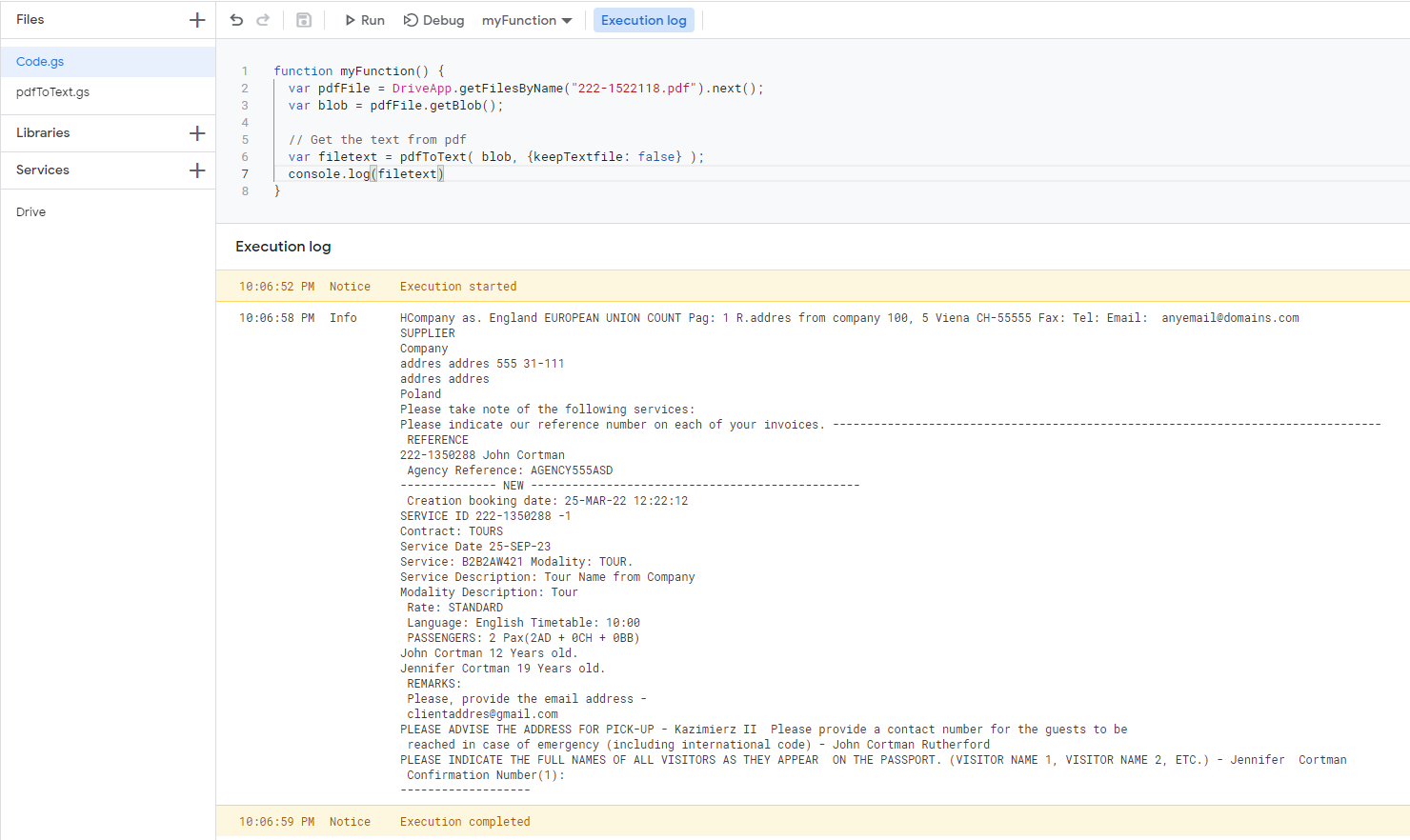
I used Mogsdad's library pdfToText
Reference: Get text from PDF in Google