I have the following dataset:
df = pd.DataFrame ({"a": [1,2,3,4,5,6,7,8,9,1,11,12,13,14,15,16,17,18,19,20],
'b':[1,2,3,4,50,60,70,8,9,10,110,120,130,140,150,16,17,18,19,20],
'c':[np.nan,2.2,3.4,np.nan,40.9,60.2,np.nan,8.2,8.9,10.1,np.nan,120.2,
130.07,140.23,np.nan,16.054,17.20,18.1,np.nan,20.1],
'd': [100, np.nan,np.nan, 500,np.nan, np.nan,500,
np.nan,np.nan,np.nan,100, np.nan,np.nan, np.nan,500,
np.nan,np.nan, np.nan,100,np.nan ]}
)
I am trying to plot the data based on the following conditions:
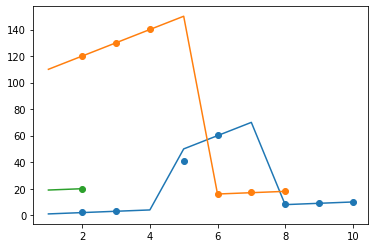
Between 100 to the next 100 in column 'd' I want to have one plot having column 'a' in the x axis, and scatterplot of column 'b' and line plot of 'c' in the y axis.
That is I will be having 3 different plots. First one from index 0 to 10, second one from index 10 to index 18, third one from 18 to 20. (I can generate this using for loop)Within each plot I want segmented lineplot based on the location 500 value in column 'd',i.e., for the first plot from index 0-3 one lineplot, from index 3-6 another and from index 6-10 another lineplot.( I can't make the segmented lineplot)
I am using the following codes:
index = index [len(df)]
index1 = index1 [len(df)]
for k in range (len(index)-1):
x = df['a'][index[k] 1:index[k 1]]
y = df['c'][index[k] 1:index[k 1]]
y1 = df['b'][index[k] 1:index[k 1]]
plt.scatter(x, y)
plt.plot(x, y1)
plt.savefig('plot' str(k 1000) '.png')
plt.clf()
My first plot look like this: (But want to have three segmented
lineplot not the continuous one (that is line from index 0-3 should not be connected with 3-6 and so on) 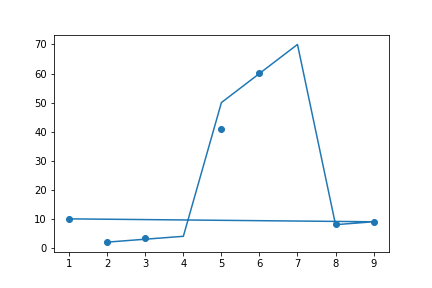
Sorry for the rather long question and thx:)
CodePudding user response:
The expected output is unclear, but here is a general strategy to split your dataset in groups with help of 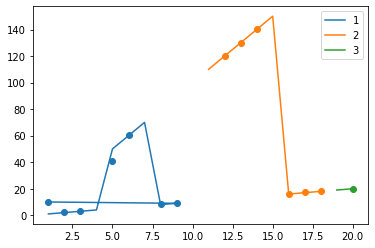
option 3
ax = plt.subplot()
group = df['d'].eq(100).cumsum()
for name, g in df.groupby(group):
g = g.reset_index()
ax.scatter(g.index 1, g['c'])
ax.plot(g.index 1, g['b'])