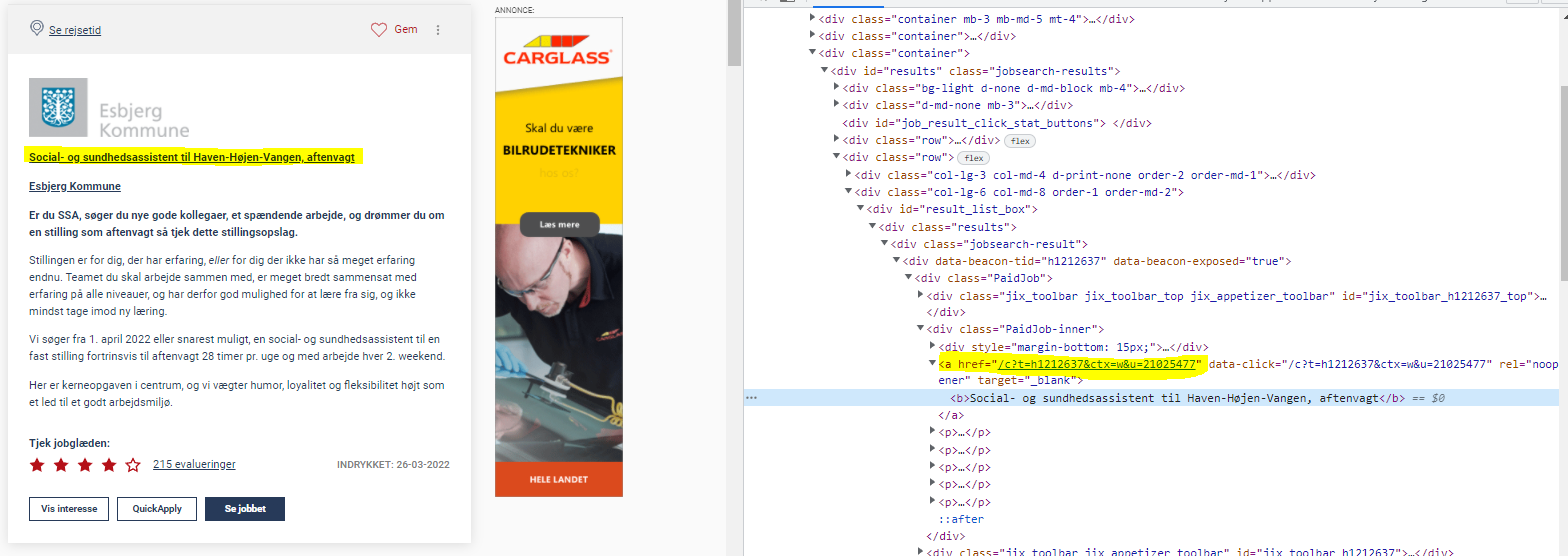
I have so far created the below code, to extract all the informations, but I cant figure out how to extract the link. I have tried with a for loop, but i get differents links. I really hope anyone can point me at the right direction.
def extract(page, tag):
url = f"https://www.jobindex.dk/jobsoegning?page ={page} &q ={tag}"
r = requests.get(url, headers)
soup = BeautifulSoup(r.content.decode("utf-8"), "html.parser")
return soup
def transform(soup):
divs = soup.find_all("div", class_="jobsearch-result")
for item in divs:
title = item.find_all("b")[0].text.strip()
company = item.find_all("b")[1].text.strip()
published_date = item.find("time").text.strip()
summary = item.find_all("p")[1].text.strip()
job_location = item.find_all("p")[0].text.strip()
job_url = item.find_all("href")
job = {
"title" : title,
"company" : company,
"published_date" : published_date,
"summary" : summary,
"job_location" : job_location,
"Job_url" : job_url
}
joblist.append(job)
return
CodePudding user response:
You can combine an attribute = value css selector with contains * operator to target onclick attribute by a substring. Add to that selector list :has to specify element with matched onclick attribute must have immediate child b tag which restricts matches to those with the bold job title
[data-click*="u="]:has(> b)
import requests
from bs4 import BeautifulSoup
def extract(page, tag):
headers = {'User-Agent':'Mozilla/5.0'}
url = f"https://www.jobindex.dk/jobsoegning?page={page}&q={tag}"
r = requests.get(url, headers)
soup = BeautifulSoup(r.content.decode("utf-8"), "html.parser")
return soup
def transform(soup):
divs = soup.find_all("div", class_="jobsearch-result")
for item in divs:
title = item.find_all("b")[0].text.strip()
company = item.find_all("b")[1].text.strip()
published_date = item.find("time").text.strip()
summary = item.find_all("p")[1].text.strip()
job_location = item.find_all("p")[0].text.strip()
job_url = item.select_one('[data-click*="u="]:has(> b)')['href']
job = {
"title" : title,
"company" : company,
"published_date" : published_date,
"summary" : summary,
"job_location" : job_location,
"Job_url" : job_url
}
joblist.append(job)
return
joblist = []
soup = extract(1, "python")
#print(soup)
transform(soup)
print(joblist)