I have two lists, one that contains the user input and the other one that contains the mapping.
The user input looks like this :
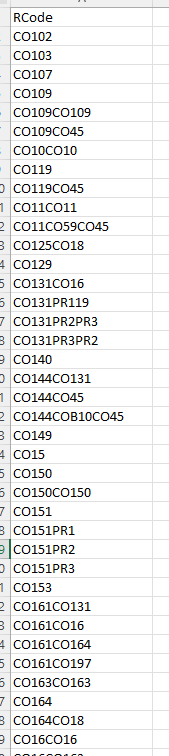
The mapping looks like this :
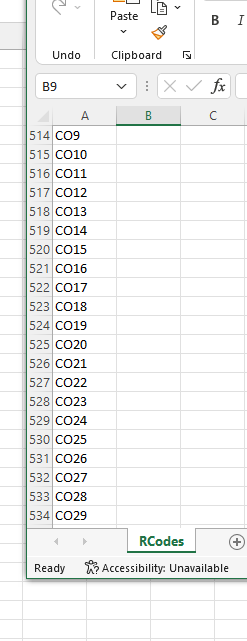
I am trying to split the strings in the user input list. Sometime they enter one record as CO109CO45 but in reality these are two codes and don't belong together. They need to be separated with a comma or space as such CO109,CO45.
There are many examples that have the same behavior and i was thinking to use a mapping list to match and split. Is this something that can be done? What do you suggest? Thanks in advance for your help!
CodePudding user response:
Use a combination of look ahead and look behind regex in the split.
df = pd.DataFrame({'RCode': ['CO109', 'CO109CO109']})
print(df)
RCode
0 CO109
1 CO109CO109
df.RCode.str.split('(?<=\d)(?=\D)')
0 [CO109]
1 [CO109, CO109]
Name: RCode, dtype: object
CodePudding user response:
You can try with regex:
import re
l = ['CO2740CO96', 'CO12', 'CO973', 'CO870CO397', 'CO584', 'CO134CO42CO685']
df = pd.DataFrame({'code':l})
df.code = df.code.str.findall('[A-Za-z] \d ')
print(df)
Output:
code
0 [CO2740, CO96]
1 [CO12]
2 [CO973]
3 [CO870, CO397]
4 [CO584]
5 [CO134, CO42, CO685]
CodePudding user response:
I usually use something like this, for an input original_list:
output_list = [
[
('CO' target).strip(' ,')
for target in item.split('CO')
]
for item in original_list
]
There are probably more efficient ways of doing it, but you don't need the overhead of dataframes / pandas, or the hard-to-read aspects of regexes.
If you have a manageable number of prefixes ("CO", "PR", etc.), you can set up a recursive function splitting on each of them. - Or you can use .find() with the full codes.