I have a list of excel files (.xlsx,.xls), I'm trying to get headers of each of these files after loaded.
Here I have taken a one excel file and loaded into pandas as.
pd.read_excel("sample.xlsx")
output is:
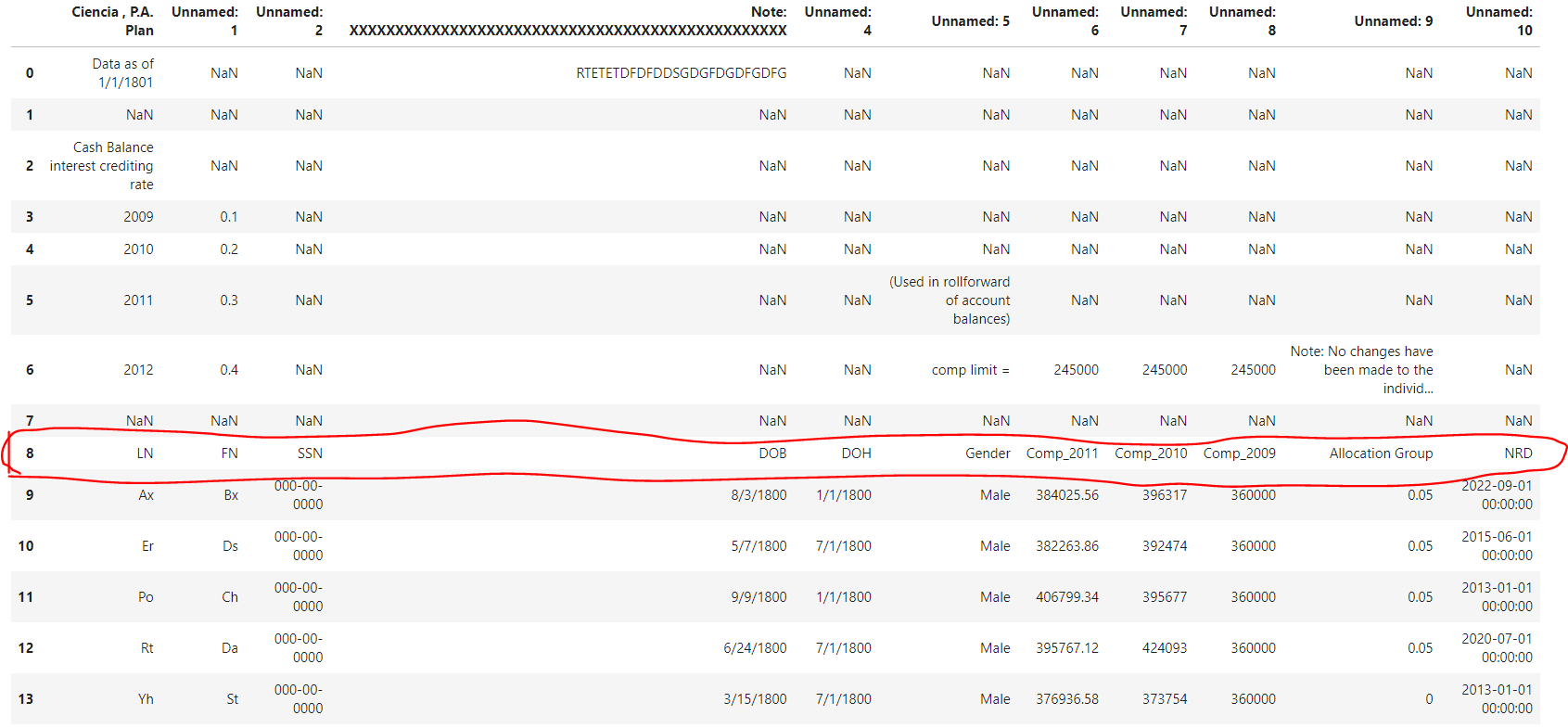
Here we would like to get an header information as per our requirement, here in the attached image the required headers are existed at index 8 as you can see in red color coded.
pd.read_excel('sample.xlsx',skiprows=9)
as we know now we have a correct header at 8 i can go back and specify in read_excel as skip_rows at 8 so that it reads from this index and headers will be appeared as.
How to handle this type of cases programmatically among a list of excel files where we don't know where the header is existed? in this case we have known that header is at 8. but what if we don't know this in other files.
Sample file can be downloaded for your ref:
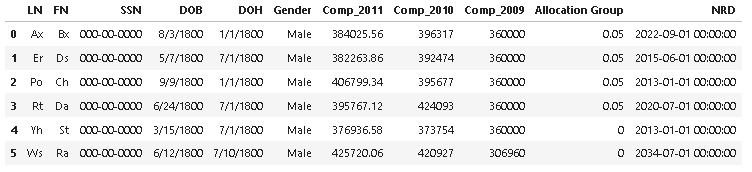
Based on your comment, you can use the following condition:
df[df.notna().sum(axis = 1)==11].index[0]
CodePudding user response:
Use:
df = pd.read_excel('sample_file.xlsx')
m1 = df.shift(fill_value=0).isna().all(axis=1)
m2 = df.notna().all(axis=1)
df = df[(m1 & m2).cummax()]
df = df.set_axis(df.iloc[0].rename(None), axis=1).iloc[1:].reset_index(drop=True)
print (df)
LN FN SSN DOB DOH Gender Comp_2011 Comp_2010 \
0 Ax Bx 000-00-0000 8/3/1800 1/1/1800 Male 384025.56 396317
1 Er Ds 000-00-0000 5/7/1800 7/1/1800 Male 382263.86 392474
2 Po Ch 000-00-0000 9/9/1800 1/1/1800 Male 406799.34 395677
3 Rt Da 000-00-0000 6/24/1800 7/1/1800 Male 395767.12 424093
4 Yh St 000-00-0000 3/15/1800 7/1/1800 Male 376936.58 373754
5 Ws Ra 000-00-0000 6/12/1800 7/10/1800 Male 425720.06 420927
Comp_2009 Allocation Group NRD
0 360000 0.05 2022-09-01 00:00:00
1 360000 0.05 2015-06-01 00:00:00
2 360000 0.05 2013-01-01 00:00:00
3 360000 0.05 2020-07-01 00:00:00
4 360000 0 2013-01-01 00:00:00
5 306960 0 2034-07-01 00:00:00