I have a sample dataset. Here is:
import pandas as pd
import numpy as np
df = {'Point1': [50,50,50,45,45,35,35], 'Point2': [48,44,30,35,33,34,32], 'Dist': [4,6,2,7,8,3,6]}
df = pd.DataFrame(df)
df
And its output is here:
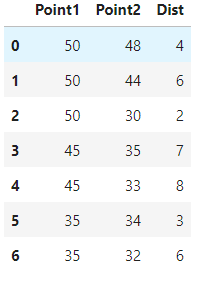
My goal is to find dist value with its condition and point2 value for each group of point1. Here is my code. (It gives an error)
if df['dist'] < 5 :
df1 = df[df['dist'].isin(df.groupby('Point1').max()['Dist'].values)]
else :
df1 = df[df['dist'].isin(df.groupby('Point1').min()['Dist'].values)]
df1
And here is the expected output:
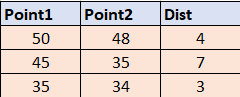
So, if there is exist Dist value less than 5, I would like to take the max one of these groups. If no, I would like to take the min one. I hope it would be clear.
CodePudding user response:
IIUC, you want to find the closest Dist to 5, with prority for values lower than 5.
For this you can compute two columns to help you sort the values in order of priority and take the first one. Here 'cond' sort by ≤5 first, then >5, and cond2 by absolute distance to 5.
thresh = 5
(df
.assign(cond=df['Dist'].gt(thresh),
cond2=df['Dist'].sub(thresh).abs(),
)
.sort_values(by=['cond', 'cond2'])
.groupby('Point1', as_index=False).first()
.drop(columns=['cond', 'cond2'])
)
output:
Point1 Point2 Dist
0 35 34 3
1 45 35 7
2 50 48 4
NB. this is also sorting by Point1 in the process, if this is unwanted on can create a function to sort a dataframe this way and apply it per group. Let me know if this is the case
CodePudding user response:
Since you are using pandas DataFrame you can use the brackets syntax to filter the the data
In your case:
df[df['Dist']] < 5
About the second part of the question, it was a little confusing, can you explain more about the "take the max one of these groups. If no, I would like to take the min one"