I have a Mentor class in which I have an ID for each mentor and an ArrayList of mentee IDs, like this:
public class Mentor {
int mentorId;
ArrayList<Integer> mentees = new ArrayList<>();
public Mentor(int mentorId, ArrayList<Integer> mentees) {
this.mentorId = mentorId;
this.mentees = mentees ;
}
}
The problem is that some mentees can be mentors too.
I would like to somehow get a count of all of the mentees associated to the top mentor as well as how many mentors are under the top mentor.
So, basically, if a mentor has a mentee, who is also a mentor, then this mentor's mentees are also associated to the top mentor.
So, my thinking was to loop through the mentee-list and see if any of the id's match an ID of Mentor. If true, Add this mentor's list of mentees to a list and loop again, but this will not work dynamically.
My main class looks something like this:
ArrayList<Mentor> mentors = new ArrayList<>();
ArrayList<Integer> mentees = new ArrayList<>();
ArrayList<Integer> mentees2 = new ArrayList<>();
mentees.add(2);
mentees.add(3);
mentees2.add(4);
mentees2.add(5);
//[1,{2,3}]
mentors.add(new Mentor(1, mentees));
//[2,{4,5}]
mentors.add(new Mentor(2, mentees2));
int mentorCount = 0;
int menteeCount = 0;
for (Mentor mentor : mentors) {
for (Integer mentee : mentees) {
mentorCount ;
if (mentee == mentor.mentorId){
mentorCount ;
//add each mentee to arraylist and start the process again, but is there an easier way to do this.
}
}
}
I was wondering if there is a way of solving this, maybe using streams?
CodePudding user response:
I would recommend using good object oriented design, you shouldn't just use integer id's like that, because in this situation you could simply make an ArrayList of Person objects Where Mentees, and Mentors Inherit from Person. Then you can check if a Person is an instance of Mentee versus Mentor:
for (Person p : people) {
if (p instanceof Mentor)
{
// Mentor logic
}
if (p instanceof Mentee)
{
// Mentee Logic
}
}
CodePudding user response:
You should do something like a depth-first or breadth-first search (*):
- Maintain a
Set<Integer>containing all the people you have already seen. - Maintain a queue of some kind (e.g. an
ArrayDeque), of people you are going to check. - Put the first person (or any number of people, actually) into this queue.
- Then, while the queue is not empty:
- Take the next person in the queue
- If you've already seen them, go to the next item in the queue
- If you've not already seen them, put the person into the seen set; add all of their mentees into the queue
That's it. The number of people at the end is the size of the seen set.
(*) Whether you do depth-first or breadth-first search depends on which end of the queue you add mentees to: adding them to the same end that you remove them from results in depth-first search; adding them to the other end results in breadth-first search. If you don't care which, choose either.
CodePudding user response:
Firstly, let's briefly recap the task.
You have a set of mentors, each mentor has a collection of mentees. Some of them might happen also to be mentors and so on.
Class design
From the perspective of class design, the solution is pretty simple: you need only one class to describe this relationship - Mentor. And each Mentor should hold a reference to a collection of Mentors (not integer ids).
In your domain model, as you described it, there's no substantial difference between a mentor and a mentee. Mentor points to other mentors - is a simplest way to model that. Mentee is just an edge case, a mentor which has an empty collection of mentors.
You don't need to include classes and features in your application that doesn't bring benefit.
Data structure
From the perspective of data structures, this problem can be described very well with an acyclic disjointed Graph.
Acyclic because if we consider the relationship between mentors when a mentor could indirectly point at themself (i.e. a mentor N has a mentee, with in tern points to another mentee that happens to be also a mentor of mentor N) the task becomes ambiguous. Therefore, I'm making an assumption that no one can be a mentor to himself.
I also depicted this data structure as disjointed because mentors in this model (as well as in real life) can form isolated groups, which in graph theory called connected components. That means that there could be several mentors with the same count of mentee, which happens to be the largest.
Depth first search
In order to find all the vertices (mentors) connected with a particular mentor, we have a classic traversal algorithm, which is called Depth first search (DFS). The core idea of DFS is to peek a single neighbor of the given vertex, then in turn peek one of its neighbors and so on until the hit the vertex that doesn't point to the other vertex (i.e. maximum depth is reached). And then it should be done with every other neighbors of the previously visited vertices.
There are two ways to implement DFS.
Iterative approach
For that, we need a stack. It will store all unvisited neighbors of the previously encountered vertexes. The last vertex from each list of neighbors in every branch will be explored first because it will be placed on the top of the stack. Then it will get removed from the stack and it's neighbors will be placed on the stack. This process repeats in a loop until the stack contains at least one element.
The most performant choice of collection for the stack is ArrayDeque.
Because this approach require continuous modification of the stack by adding and removing vertices, it isn't suitable to be implemented with Stream IPA.
Recursive approach
The overall principle is the same as described above, but we don't need to provide a stack explosively. The call stack of the JVM will be utilized for that purpose.
With this approach, there's also some room to apply streams. For that reason, I've chosen the recursive implementation. Also, its code is probably a bit easier to understand. But keep in mind that recursion has certain limitations, especially in Java, and not suitable for processing a large set of data.
Recursion
A quick recap on recursion.
Every recursive implementation consists of two parts:
- Base case - that represents a simple edge-case for which the outcome is known in advance. For this task, the base case is the given vertex has no neighbors. That means
menteesCountof this vertex needs to be set to0because it has no mentee. And the return value for the base case is1because this vertex, in turn, is a valid mentee of another vertex that holds a reference to it. - Recursive case - a part of a solution where recursive calls a made and where the main logic resides.
The recursive case could be implemented using streams and entails recursive invocation of the for every neighbor of the given vertex. Each of these values will contribute to the menteesCount of the given vertex.
The value returned by the method will be menteesCount 1 because for the vertex which triggered this method call, the given vertex will be a mentee as well as its mentees.
Implementation
Class mentor basically serves as a vertex of the graph. Each vertex has a unique id and collection of adjacent vertexes.
Also, in order to reuse values obtained by performing DFS I've added a field menteesCount which is initially initialized to -1 in order to distinguish between vertices that has no adjacent vertices (i.e. menteesCount has to be 0) and vertices which value wasn't calculated. Every value will be established only ones and then reused (another approach will be to utilize a map for that purpose).
Method getTopMentors() iterates over the collection of vertices and invokes DFS for every vertex which value wasn't calculated yet. This method returns a list of mentors with the highest number of associated mentees
Method addMentor() that takes a vertex id, and id of its neighbors (if any) was added in order to interact with the graph in a convenient way.
Map mentorById contains every vertex that was added in the graph and, as its name suggests, allows retrieving it based on the vertex id.
public class MentorGraph {
private Map<Integer, Mentor> mentorById = new HashMap<>();
public void addMentor(int mentorId, int... menteeIds) {
Mentor mentor = mentorById.computeIfAbsent(mentorId, Mentor::new);
for (int menteeId: menteeIds) {
mentor.addMentee(mentorById.computeIfAbsent(menteeId, Mentor::new));
}
}
public List<Mentor> getTopMentors() {
List<Mentor> topMentors = new ArrayList<>();
for (Mentor mentor: mentorById.values()) {
if (mentor.getCount() != -1) continue;
performDFS(mentor);
if (topMentors.isEmpty() || mentor.getCount() == topMentors.get(0).getCount()) {
topMentors.add(mentor);
} else if (mentor.getCount() > topMentors.get(0).getCount()) {
topMentors.clear();
topMentors.add(mentor);
}
}
return topMentors;
}
private int performDFS(Mentor mentor) {
if (mentor.getCount() == -1 && mentor.getMentees().isEmpty()) { // base case
mentor.setCount(0);
return 1;
}
int menteeCount = // recursive case
mentor.getMentees().stream()
.mapToInt(m -> m.getCount() == -1 ? performDFS(m) : m.getCount() 1)
.sum();
mentor.setCount(menteeCount);
return menteeCount 1;
}
public static class Mentor {
private int id;
private Set<Mentor> mentees = new HashSet<>();
private int menteesCount = -1;
public Mentor(int id) {
this.id = id;
}
public boolean addMentee(Mentor mentee) {
return mentees.add(mentee);
}
// getters, setter for menteesCount, equeals/hashCode
}
}
An example of the graph used as a demo.
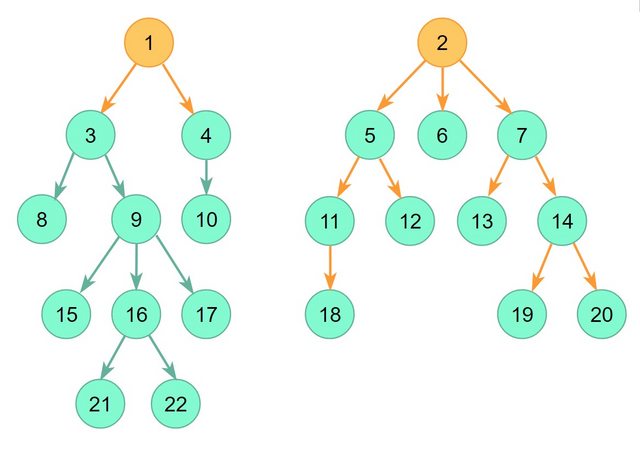
main() - the code models the graph shown above
public static void main(String[] args) {
MentorGraph graph = new MentorGraph();
graph.addMentor(1, 3, 4);
graph.addMentor(2, 5, 6, 7);
graph.addMentor(3, 8, 9);
graph.addMentor(4, 10);
graph.addMentor(5, 11, 12);
graph.addMentor(6);
graph.addMentor(7, 13, 14);
graph.addMentor(8);
graph.addMentor(9, 16, 17, 18);
graph.addMentor(10);
graph.addMentor(11, 18);
graph.addMentor(12);
graph.addMentor(13);
graph.addMentor(14, 19, 20);
graph.addMentor(15);
graph.addMentor(16, 21, 22);
graph.addMentor(17);
graph.addMentor(18);
graph.addMentor(19);
graph.addMentor(20);
graph.addMentor(21);
graph.addMentor(22);
graph.getTopMentors()
.forEach(m -> System.out.printf("mentorId: %d\tmentees: %d\n", m.getId(), m.getCount()));
}
Output
mentorId: 1 mentees: 10
mentorId: 2 mentees: 10