I have a Pyspark dataframe in the below format:
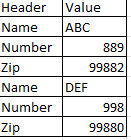
And I need to convert it into something like this:
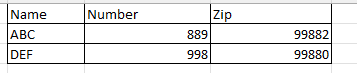
Any help ?
CodePudding user response:
Create a new column row_num using row_number and then use pivot. See below logic for details -
Input Data
df = spark.createDataFrame(data = [("Name", "ABC"),
("Number", "889"),
("Zip", "99882"),
("Name", "DEF"),
("Number", "998"),
("Zip", "99880")],
schema = ["Header", "Value"]
)
df.show()
------ -----
|Header|Value|
------ -----
| Name| ABC|
|Number| 889|
| Zip|99882|
| Name| DEF|
|Number| 998|
| Zip|99880|
------ -----
Now create a new column as row_num using row_number function.
from pyspark.sql.functions import *
from pyspark.sql import Window
df1 = df.withColumn("row_num", row_number().over(Window.partitionBy("Header").orderBy("Value")))
Finally, groupBy this newly created column and use pivot on Header column.
df1.groupBy("row_num").pivot("Header").agg(first("Value")).drop("row_num").show()
---- ------ -----
|Name|Number| Zip|
---- ------ -----
| ABC| 889|99880|
| DEF| 998|99882|
---- ------ -----