Hi I've two dataframes like this:
import spark.implicits._
import org.apache.spark.sql._
val transformationDF = Seq(
("A_IN", "ain","String"),
("ADDR_HASH","addressHash","String")
).toDF("db3Column", "hudiColumn","hudiDatatype")
val addressDF=Seq(
("123","uyt"),
("124","qwe")
).toDF("A_IN", "ADDR_HASH")
Now I wanted to rename the column and change the datatype on values mentioned in the transformationdf.The hudicolumn name and hudidatatype from transformationDF will become the column name and datatype of addressDF. I tried code like this to change but doesn't work:
var db3ColumnName:String =_
var hudiColumnName:String =_
var hudiDatatypeName:String = _
for (row <- transformationDF.rdd.collect)
{
db3ColumnName = row.mkString(",").split(",")(0)
hudiColumnName= row.mkString(",").split(",")(1)
hudiDatatypeName = row.mkString(",").split(",")(2)
addressDF.withColumnRenamed(db3ColumnName,hudiColumnName).withColumn(hudiColumnName,col(hudiColumnName).cast(hudiDatatypeName))
}
Now when I print the addressDF thechanges do not reflect.
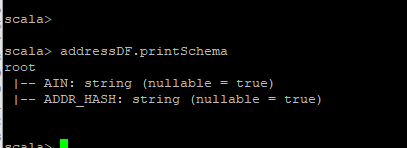
Can anyone help me with this .
CodePudding user response:
When you use withColumnRenamed or withColumn, it returns a new Dataset, so you should do like this:
var db3ColumnName: String = null
var hudiColumnName: String = null
var hudiDatatypeName: String = null
for (row <- transformationDF.rdd.collect) {
db3ColumnName = row.mkString(",").split(",")(0)
hudiColumnName = row.mkString(",").split(",")(1)
hudiDatatypeName = row.mkString(",").split(",")(2)
addressDF = addressDF.withColumnRenamed(db3ColumnName, hudiColumnName).withColumn(hudiColumnName, col(hudiColumnName).cast(hudiDatatypeName))
}
addressDF.printSchema()
Print the addressDF will return:
root
|-- ain: string (nullable = true)
|-- addressHash: string (nullable = true)
CodePudding user response:
This is a textbook case that calls for using foldLeft:
val finalDF = transformationDF.collect.foldLeft(addressDF){ case (df, row) =>
{
val db3ColumnName = row.getString(0)
val hudiColumnName = row.getString(1)
val hudiDatatypeName = row.getString(2)
df.withColumnRenamed(db3ColumnName, hudiColumnName)
.withColumn(hudiColumnName, col(hudiColumnName).cast(hudiDatatypeName))
}
}
Datasets in Spark are immutable and each operation that "modifies" a dataset actually returns a new object leaving the one that the operation was called on unchanged. The above foldLeft effectively starts with addressDF and chains all the transformations onto intermediate objects that get passed as the first argument in the second argument list. The return value of the current iteration becomes the input of the next iteration. The return value of the last iteration is the return value of foldLeft itself.