My data:
data <- structure(list(col1 = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), col2 = c(0L, 1L, 1L, 0L, 0L,
1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 0L, 1L, 0L, 1L, 0L)), class = "data.frame", row.names = c(NA,
-18L))
I want to get 2 new columns based on col1 and col2.
- column 3 is obtained: We leave units if there is zero in the second column, 2 are simply transferred.
- column 4 will turn out: We leave units if there is one in the second column, 2 are simply transferred.
What I want to get:
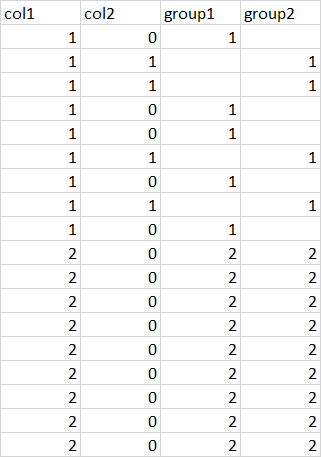
data <- structure(list(col1 = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), col2 = c(0L, 1L, 1L, 0L, 0L,
1L, 0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), group1 = c(1L,
NA, NA, 1L, 1L, NA, 1L, NA, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L), group2 = c(NA, 1L, 1L, NA, NA, 1L, NA, 1L, NA, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L)), class = "data.frame", row.names = c(NA,
-18L))
CodePudding user response:
A solution that uses tidyr::pivot_wider():
library(dplyr)
data %>%
mutate(id = 1:n(), name = paste0("group", col2 1), value = 1) %>%
tidyr::pivot_wider() %>%
mutate(col2 = replace(col2, col1 == 2, 0),
across(starts_with("group"), replace, col1 == 2, 2)) %>%
select(-id)
# A tibble: 18 x 4
col1 col2 group1 group2
<int> <dbl> <dbl> <dbl>
1 1 0 1 NA
2 1 1 NA 1
3 1 1 NA 1
4 1 0 1 NA
5 1 0 1 NA
6 1 1 NA 1
7 1 0 1 NA
8 1 1 NA 1
9 1 0 1 NA
10 2 0 2 2
11 2 0 2 2
12 2 0 2 2
13 2 0 2 2
14 2 0 2 2
15 2 0 2 2
16 2 0 2 2
17 2 0 2 2
18 2 0 2 2