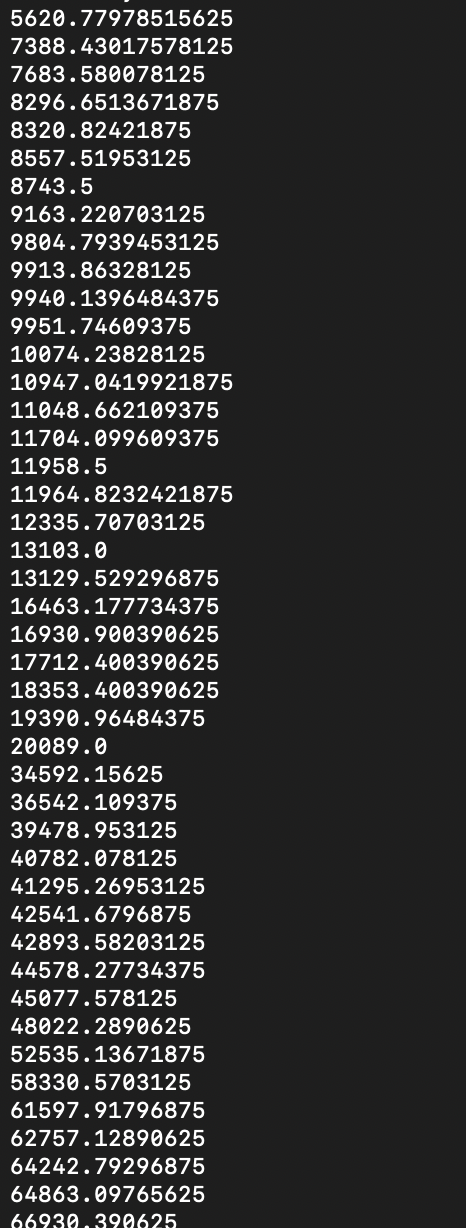
I currently have the numbers above in a list. How would you go about adding similar numbers (by nearest 850) and finding average to make the list smaller.
For example I have the list
l = [2000,2200,5000,2350]
In this list, i want to find numbers that are similar by n 500
So I want all the numbers similar by n 500 which are 2000,2200,2350 to be added and divided by the amount there which is 3 to find the mean. This will then replace the three numbers added. so the list will now be l = [2183,5000]
As the image above shows the numbers in the list. Here I would like the numbers close by n 850 to all be selected and the mean to be found
CodePudding user response:
It seems that you look for a clustering algorithm - something like K-means.
This algorithm is implemented in scikit-learn package
After you find your K means, you can count how many of your data were clustered with that mean, and make your computations.
However, it's not clear in your case what is K. You can try and run the algorithm for several K values until you get your constraints (the n 500 distance between the means)
CodePudding user response:
You just need a conditional list comprehension like this:
l = [2000,2200,5000,2350]
n = 2000
a = [ (x) for x in l if (x < (n 500)) ]
Then you can average with
np.mean(a)
or whatever method you prefer.