I am quite new to Pandas and would like to find out how I can read and then write to a DataFrame row by from in a loop.
Input information
Index lemmatized_text MulNB
1 item inexpens NaN
2 overall exper NaN
3 screen n't co NaN
4 screen not co NaN
5 've view nume NaN
Create the pandas DataFrame
df10 = pd.DataFrame(data, columns = ['MulNB', 'lemmatized_text'])
Attempted code to loop through the information:
for i in range(1,len(df10)):
test=df10['lemmatized_text'].loc[i]
df10['MulNB'].loc[i]=model.predict(vec.transform(test))
i =1
Currently it iterates until line 10 and then it stops and shows the following:
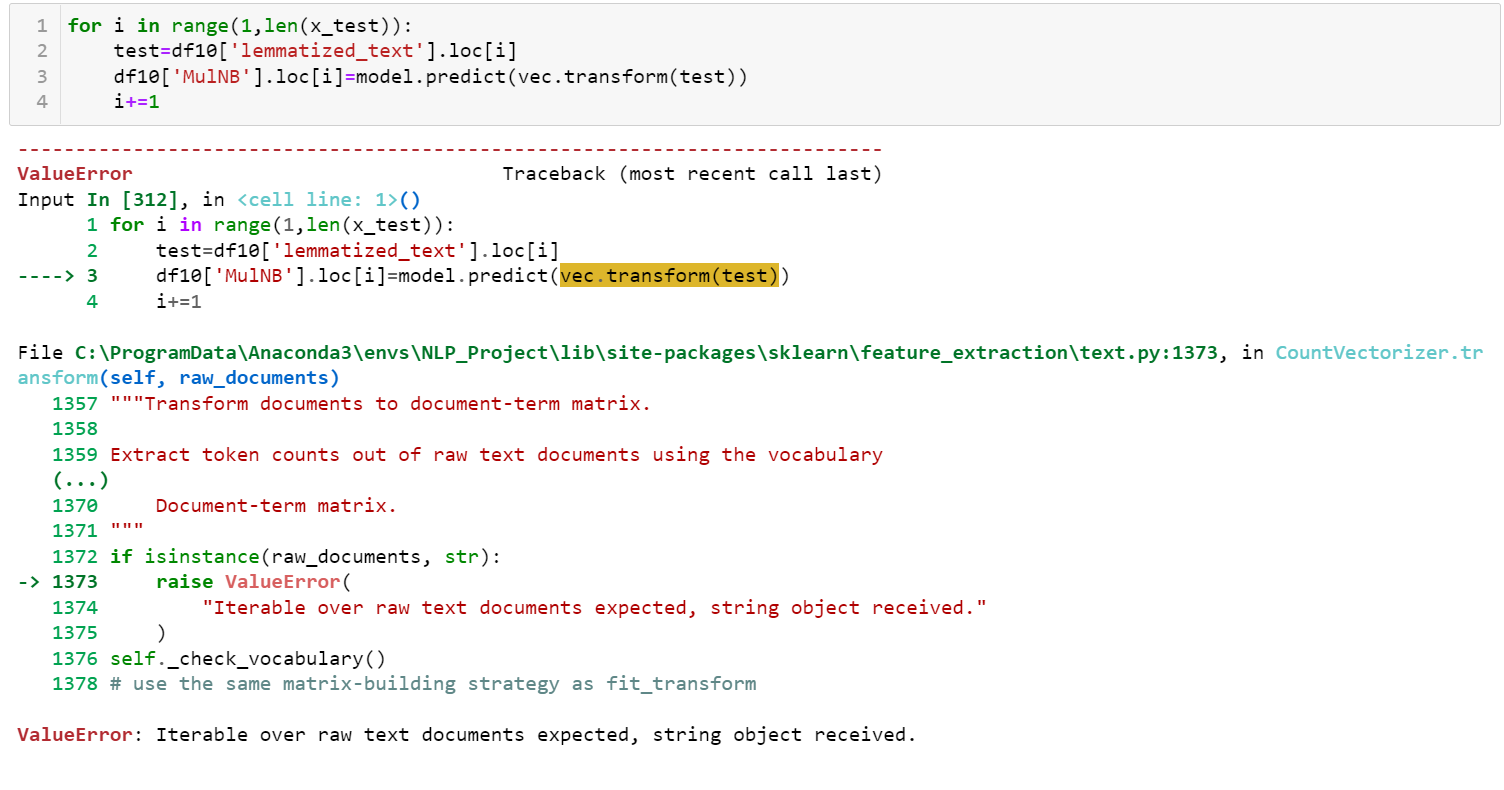
Thank you for any assistance on this.
CodePudding user response:
Instead of the loop, you could use apply:
df10['MulNB'] = df10['lemmatized_text'].apply(lambda test: model.predict(vec.transform([test])))
but then again, it may be more efficient to use a list comprehension.
df10['MulNB'] = [model.predict(vec.transform([test])) for test in df10['lemmatized_text']]
I don't know how your model is set up but if it's a text mining model, I think it should be vectorized:
df10['MulNB'] = model.predict(vec.transform(df10['lemmatized_text']))
CodePudding user response:
To update/iterate over rows in Panadas Dataframe I would recommend you to checkout iterrows() provided by Pandas.
for i, row in df10.iterrows():
test = df10.loc[i,'lemmatized_text']
df10.loc[i,'MulNB'] = model.predict(vec.transform(test))
Other Alternative is to use List Comprehension.