Overview: I'm working with some data, within which has information representing 3 different types of stores. The data is split into bins, which represent the range of square footage of the stores. The Quantity column is how many of those types of stores, fall into that bin range. The last column being revenue per sq ft. The data looks like this:
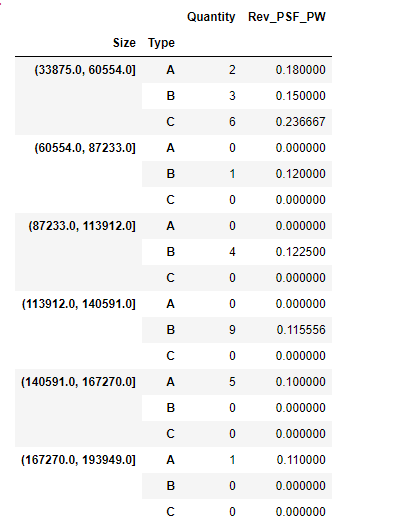
But you can create the dataframe using this dictionary below:
df =
{'Quantity': {(Interval(33875.0, 60554.0, closed='right'), 'A'): 2,
(Interval(33875.0, 60554.0, closed='right'), 'B'): 3,
(Interval(33875.0, 60554.0, closed='right'), 'C'): 6,
(Interval(60554.0, 87233.0, closed='right'), 'A'): 0,
(Interval(60554.0, 87233.0, closed='right'), 'B'): 1,
(Interval(60554.0, 87233.0, closed='right'), 'C'): 0,
(Interval(87233.0, 113912.0, closed='right'), 'A'): 0,
(Interval(87233.0, 113912.0, closed='right'), 'B'): 4,
(Interval(87233.0, 113912.0, closed='right'), 'C'): 0,
(Interval(113912.0, 140591.0, closed='right'), 'A'): 0,
(Interval(113912.0, 140591.0, closed='right'), 'B'): 9,
(Interval(113912.0, 140591.0, closed='right'), 'C'): 0,
(Interval(140591.0, 167270.0, closed='right'), 'A'): 5,
(Interval(140591.0, 167270.0, closed='right'), 'B'): 0,
(Interval(140591.0, 167270.0, closed='right'), 'C'): 0,
(Interval(167270.0, 193949.0, closed='right'), 'A'): 1,
(Interval(167270.0, 193949.0, closed='right'), 'B'): 0,
(Interval(167270.0, 193949.0, closed='right'), 'C'): 0},
'Rev_PSF_PW': {(Interval(33875.0, 60554.0, closed='right'), 'A'): 0.18,
(Interval(33875.0, 60554.0, closed='right'), 'B'): 0.15000000000000002,
(Interval(33875.0, 60554.0, closed='right'), 'C'): 0.23666666666666666,
(Interval(60554.0, 87233.0, closed='right'), 'A'): 0.0,
(Interval(60554.0, 87233.0, closed='right'), 'B'): 0.12,
(Interval(60554.0, 87233.0, closed='right'), 'C'): 0.0,
(Interval(87233.0, 113912.0, closed='right'), 'A'): 0.0,
(Interval(87233.0, 113912.0, closed='right'), 'B'): 0.1225,
(Interval(87233.0, 113912.0, closed='right'), 'C'): 0.0,
(Interval(113912.0, 140591.0, closed='right'), 'A'): 0.0,
(Interval(113912.0, 140591.0, closed='right'), 'B'): 0.11555555555555556,
(Interval(113912.0, 140591.0, closed='right'), 'C'): 0.0,
(Interval(140591.0, 167270.0, closed='right'), 'A'): 0.1,
(Interval(140591.0, 167270.0, closed='right'), 'B'): 0.0,
(Interval(140591.0, 167270.0, closed='right'), 'C'): 0.0,
(Interval(167270.0, 193949.0, closed='right'), 'A'): 0.11,
(Interval(167270.0, 193949.0, closed='right'), 'B'): 0.0,
(Interval(167270.0, 193949.0, closed='right'), 'C'): 0.0}}
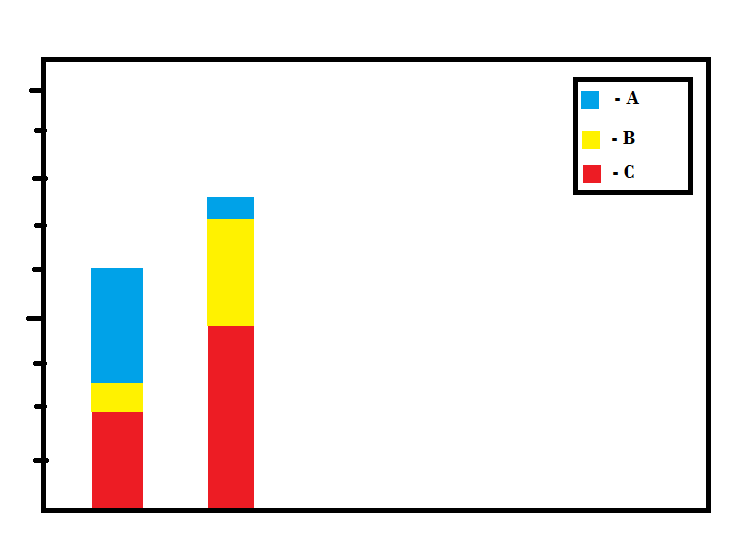
Problem: I want to display this data in a bar graph. I want the bins to be represented on the bottom, the y axis represent the revenue per sq ft and then the bars themselves, display in 3 colors, each representing the corresponding store type. So the way the colors are split would be like showing the distribution of that store type with respect to that bin. Something along these lines:
I looked up other examples and tried some things, like creating three different bar plots and trying to overlap them:
a = sns.barplot(x='Size',
y='Rev_PSF_PW',
color='red',
data=df.reset_index()[df.reset_index()['Type']=='A'],
dodge=False)
b = sns.barplot(x='Size',
y='Rev_PSF_PW',
color='yellow',
data=df.reset_index()[df.reset_index()['Type']=='B'],
dodge=False)
c = sns.barplot(x='Size',
y='Rev_PSF_PW',
color='black',
data=df.reset_index()[df.reset_index()['Type']=='C'],
dodge=False)
fig = plt.gcf()
fig.set_size_inches(12, 8)
plt.xticks(rotation=40, ha="right")
plt.xlabel(xlabel='BUILDING SF')
plt.ylabel(ylabel='AVG WEEKLY REVENUE PER SQ FT')
plt.show()
but it looks like this:
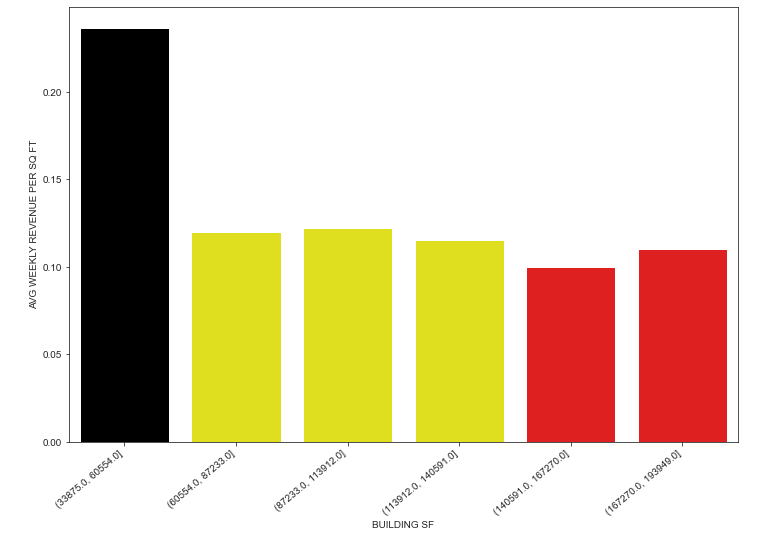
since I don't have a way of "telling" it to split the color by distribution of the store type. Anyone able to point me in the right direction? Thanks!
CodePudding user response:
Seaborn's creator isn't fond of stacked bars. But you can create them via pandas' bar plot. df.pivot can be used to convert the 'Type's into separate columns.
import pandas as pd
from pandas import Interval
df = pd.DataFrame({'Quantity': {(Interval(33875.0, 60554.0, closed='right'), 'A'): 2, (Interval(33875.0, 60554.0, closed='right'), 'B'): 3, (Interval(33875.0, 60554.0, closed='right'), 'C'): 6, (Interval(60554.0, 87233.0, closed='right'), 'A'): 0, (Interval(60554.0, 87233.0, closed='right'), 'B'): 1, (Interval(60554.0, 87233.0, closed='right'), 'C'): 0, (Interval(87233.0, 113912.0, closed='right'), 'A'): 0, (Interval(87233.0, 113912.0, closed='right'), 'B'): 4, (Interval(87233.0, 113912.0, closed='right'), 'C'): 0, (Interval(113912.0, 140591.0, closed='right'), 'A'): 0, (Interval(113912.0, 140591.0, closed='right'), 'B'): 9, (Interval(113912.0, 140591.0, closed='right'), 'C'): 0, (Interval(140591.0, 167270.0, closed='right'), 'A'): 5, (Interval(140591.0, 167270.0, closed='right'), 'B'): 0, (Interval(140591.0, 167270.0, closed='right'), 'C'): 0, (Interval(167270.0, 193949.0, closed='right'), 'A'): 1, (Interval(167270.0, 193949.0, closed='right'), 'B'): 0, (Interval(167270.0, 193949.0, closed='right'), 'C'): 0}, 'Rev_PSF_PW': {(Interval(33875.0, 60554.0, closed='right'), 'A'): 0.18, (Interval(33875.0, 60554.0, closed='right'), 'B'): 0.15000000000000002, (Interval(33875.0, 60554.0, closed='right'), 'C'): 0.23666666666666666, (Interval(60554.0, 87233.0, closed='right'), 'A'): 0.0, (Interval(60554.0, 87233.0, closed='right'), 'B'): 0.12, (Interval(60554.0, 87233.0, closed='right'), 'C'): 0.0, (Interval(87233.0, 113912.0, closed='right'), 'A'): 0.0, (Interval(87233.0, 113912.0, closed='right'), 'B'): 0.1225, (Interval(87233.0, 113912.0, closed='right'), 'C'): 0.0, (Interval(113912.0, 140591.0, closed='right'), 'A'): 0.0, (Interval(113912.0, 140591.0, closed='right'), 'B'): 0.11555555555555556, (Interval(113912.0, 140591.0, closed='right'), 'C'): 0.0, (Interval(140591.0, 167270.0, closed='right'), 'A'): 0.1, (Interval(140591.0, 167270.0, closed='right'), 'B'): 0.0, (Interval(140591.0, 167270.0, closed='right'), 'C'): 0.0, (Interval(167270.0, 193949.0, closed='right'), 'A'): 0.11, (Interval(167270.0, 193949.0, closed='right'), 'B'): 0.0, (Interval(167270.0, 193949.0, closed='right'), 'C'): 0.0}})
df.index.names = ['Size', 'Type']
df = df.reset_index()
df.pivot(index='Size', columns='Type', values='Quantity').plot.bar(stacked=True, rot=0, figsize=(15,5),
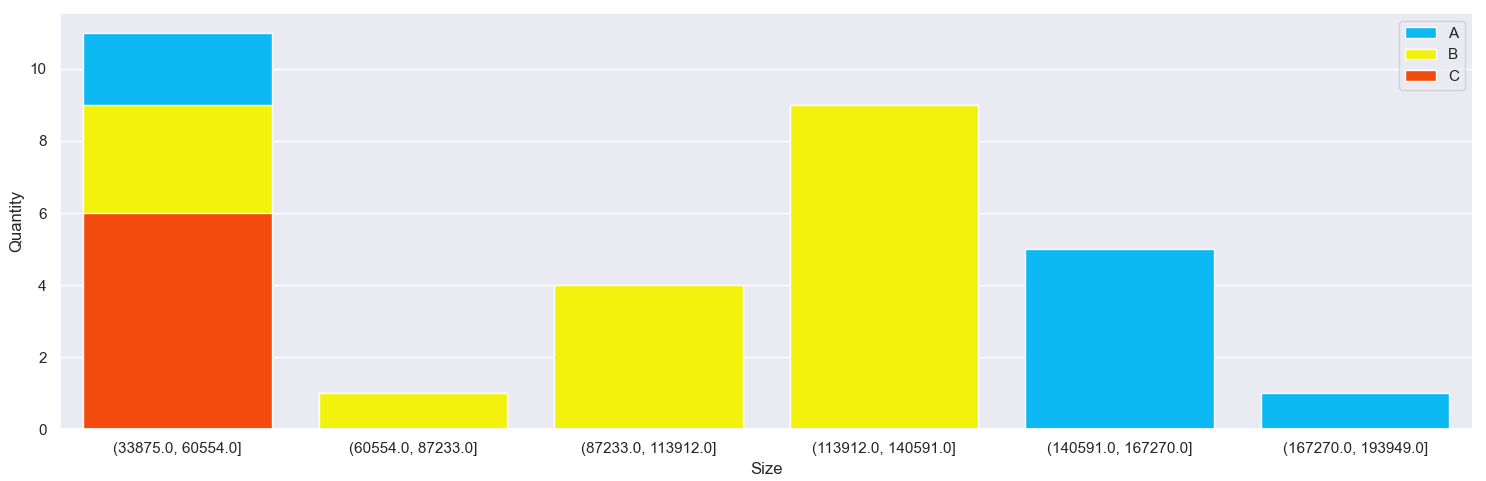
color=['DeepSkyBlue', 'Yellow', 'OrangeRed'])
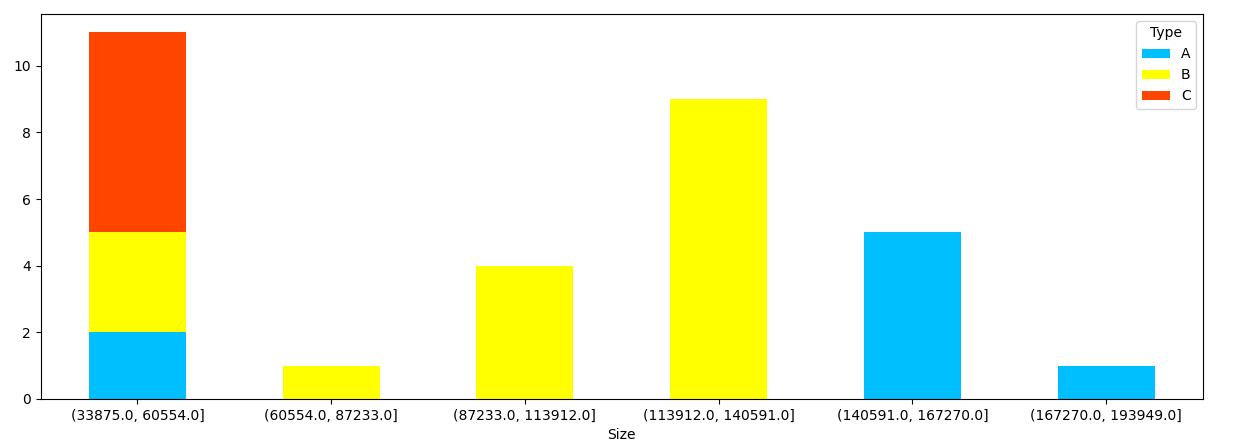
With Seaborn, stacked bars could be simulated by summing the bars and overplotting them:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from pandas import Interval
# df = ...
sns.set()
fig, ax = plt.subplots(figsize=(15, 5))
types = ['A', 'B', 'C']
for i, color in enumerate(['DeepSkyBlue', 'Yellow', 'OrangeRed']):
sns.barplot(data=df[df['Type'].isin(types[i:])], x='Size', y='Quantity', estimator=sum, ci=None, saturation=0.9,
color=color, label=types[i], ax=ax)
ax.legend()
plt.tight_layout()
plt.show()