I have two dataframes like below,
import numpy as np
import pandas as pd
df1 = pd.DataFrame({1: np.zeros(5), 2: np.zeros(5)}, index=['a','b','c','d','e'])
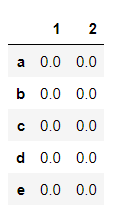
and
df2 = pd.DataFrame({'category': [1,1,2,2], 'value':[85,46, 39, 22]}, index=[0, 1, 3, 4])
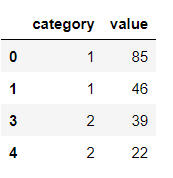
The value from second dataframe is required to be assigned in first dataframe such that the index and column relationship is maintained. The second dataframe index is iloc based and has column category which is actually containing column names of first dataframe. The value is value to be assigned.
Following is the my solution with expected output,
for _category in df2['category'].unique():
df1.loc[df1.iloc[df2[df2['category'] == _category].index.tolist()].index, _category] = df2[df2['category'] == _category]['value'].values
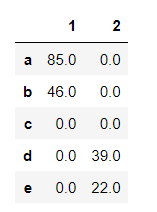
Is there a pythonic way of doing so without the for loop?
CodePudding user response:
Here's one way by replacing the 0s in df1 with NaN; pivotting df2 and filling in the NaNs in df1 with df2:
out = (df1.replace(0, pd.NA).reset_index()
.fillna(df2.pivot(columns='category', values='value'))
.set_index('index').rename_axis(None).fillna(0))
Output:
1 2
a 85.0 0.0
b 46.0 0.0
c 0.0 0.0
d 0.0 39.0
e 0.0 22.0
CodePudding user response:
One option is to pivot and update:
df3 = df1.reset_index()
df3.update(df2.pivot(columns='category', values='value'))
df3 = df3.set_index('index').rename_axis(None)
Alternative, reindex df2 (in two steps, numerical and by label), and combine_first with df1:
df3 = (df2
.pivot(columns='category', values='value')
.reindex(range(max(df2.index) 1))
.set_axis(df1.index)
.combine_first(df1)
)
output:
1 2
a 85.0 0.0
b 46.0 0.0
c 0.0 0.0
d 0.0 39.0
e 0.0 22.0