I use the following script to measure the average RGB color of the picture in a selected path. I tried to make 1 dataframe with pd.concat but it doesn't work out. I hope someone can help me.
def Innovator(ImagePath, SavePath):
for file in glob.glob(ImagePath):
print(file)
img = cv.imread(file)
scale_percent = 60
width = int(img.shape[1] * scale_percent / 100)
height = int(img.shape[0] * scale_percent / 100)
dim = (width, height)
imgr = cv.resize(img, dim, interpolation=cv.INTER_AREA)
hsv = cv.cvtColor(imgr, cv.COLOR_BGR2HSV)
blur0 = cv.medianBlur(hsv, 11)
low_yellow = np.array([10, 42, 210])
high_yellow = np.array([30, 255, 255])
mask = cv.inRange(blur0, low_yellow, high_yellow)
res = cv.bitwise_and(imgr, imgr, mask=mask)
fname = os.path.splitext(os.path.basename(file))[0]
# print(fname)
Imagefolder = str(SavePath) '\\' 'Gesegmenteerde afbeelding'
if not os.path.exists(Imagefolder):
os.makedirs(Imagefolder)
cv.imwrite(str(SavePath) f'/Gesegmenteerde afbeelding/{fname}.jpg', res)
result_df = pd.DataFrame()
#print(file)
x = res[np.all(res != 0, axis=2)].mean(axis=0)
x = pd.DataFrame(x)
#print(x)
x = pd.concat((result_df, pd.DataFrame(x)), axis=0)
df_t = x.T
df_t = pd.concat((result_df, pd.DataFrame(df_t)), axis=1)
df_t.columns = ['R', 'G', 'B']
df_t.loc['Mean'] = df_t.mean()
df_t = df_t.round(decimals=1)
print(df_t)
This is the result that I get:
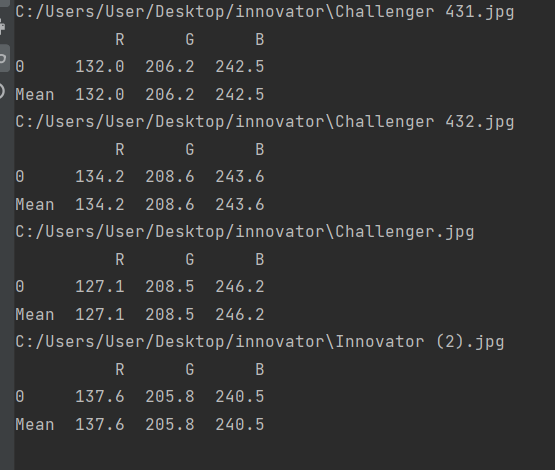
But I want just 1 dataframe with one average like this:
R G B
132 206,2 242,5
134,2 208,6 243,6
127,1 208,5 246,2
137,6 205,8 240,5
Mean:
Thanks
CodePudding user response:
Use:
def Innovator(ImagePath, SavePath):
#create list of DataFrames
dfs = []
for file in glob.glob(ImagePath):
print(file)
...
#for avoid duplicated rows
#remove df_t.loc['Mean'] = df_t.mean()
print (df_t)
#append to list
dfs.append(df_t)
#outside for loops join together
df_big = pd.concat(dfs)
CodePudding user response:
Here because you already have all the dataframes you'll need, you can store them all inside a list and pass that list inside pd.concat. Make sure that the axis = 0 (which is by default so don't change it).
Here's a dummy code of what the approach should be and the output.
data1 = [[223,123,123], [223,123,123]]
data2 = [[286,118,9], [286,118,9]]
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df_list = [df1, df2]
pd.concat(df_list)
Output -
0 1 2
0 223 123 123
1 223 123 123
0 286 118 9
1 286 118 9