I have the following dataframe:
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001L, 2020L, 'apples', 'CA', 100L),
(202002L, 2020L, 'apples', 'CA', 150L),
(202001L, 2020L, 'apples', 'USA', 400L),
(202002L, 2020L, 'apples', 'USA', 675L),
(202001L, 2020L, 'oranges', 'CA', 50L),
(202002L, 2020L, 'oranges', 'CA', 65L),
(202001L, 2020L, 'oranges', 'USA', 175L),
(202002L, 2020L, 'oranges', 'USA', 390L)],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
I need to:
a) Take df1 & split by country...use country names from df1 to apply to create df2_CA, df2_USA.
b) Generate another 2 dfs showing total sales by year by product (example uses 2020, two months only), using suffix '_annual'...so we get df2_CA_annual, df2_USA_annual.
End result:
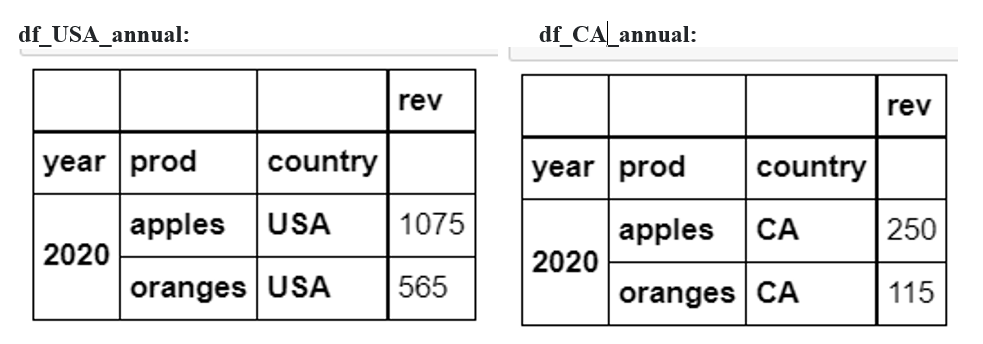
Question: My actual use case has a dozen cuts and I want to keep the coding compact. I figure I can save time using lists and for loops to create the final dfs I want. How would this be done fixing the code below?
# 1. Get dfs by country: CA and USA...df2_(country):
for x in df1['country'].unique():
locals()['df2_' x ] = df1[(df1['country'] == x ) ]
#2. Take dfs from step 1, calculate total revenue by year. Create frames df2_(country)_annual:
mylist=[df2_CA, df2_USA]
for x in mylist['country'].unique():
locals()[ 'df2_' x '_annual' ] = mylist[(mylist['country'] == x )]
x = x.groupby(['year', 'prod','country']).sum()[["rev"]]
CodePudding user response:
If you just need list of DF's then below might help:
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001, 2020, 'apples', 'CA', 100),
(202002, 2020, 'apples', 'CA', 150),
(202001, 2020, 'apples', 'USA', 400),
(202002, 2020, 'apples', 'USA', 675),
(202001, 2020, 'oranges', 'CA', 50),
(202002, 2020, 'oranges', 'CA', 65),
(202001, 2020, 'oranges', 'USA', 175),
(202002, 2020, 'oranges', 'USA', 390)],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
final_df_list = list()
for col in df1.country.unique():
final_df_list.append(df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]])
CodePudding user response:
Another approach to @VMSMani 's answer would be to leverage dictionaries:
df_annual = {}
for c in df1['country'].unique():
df_annual[c] = df1.where(df1['country'] == c).groupby(['year', 'prod', 'country']).sum()[['rev']]
the "only" difference would be that you store all the dataframes by key, so you can get them back at a later point by just calling df_annual[country], which I suppose keeps things tidier.