I am trying to expand a dataframe containing a number of columns by creating rows based on the interval between two date columns.
For this I am currently using a method that basically creates a cartesian product, which works well on small datasets, but is not good in large sets because it is very inefficient.
This method will be used on a ~ 2-million row by 50 column Dataframe spanning multiple years from min to max date. The resulting dataset will be about 3 million rows, so a more effective approach is required.
I have not succeeded in finding an alternative method which is less resource intensive. What would be the best approach for this?
My current method here:
from datetime import date
import pandas as pd
raw_data = {'id': ['aa0', 'aa1', 'aa2', 'aa3'],
'number': [1, 2, 2, 1],
'color': ['blue', 'red', 'yellow', "green"],
'date_start': [date(2022,1,1), date(2022,1,1), date(2022,1,7), date(2022,1,12)],
'date_end': [date(2022,1,2), date(2022,1,4), date(2022,1,9), date(2022,1,14)]}
df = pd.DataFrame(raw_data)
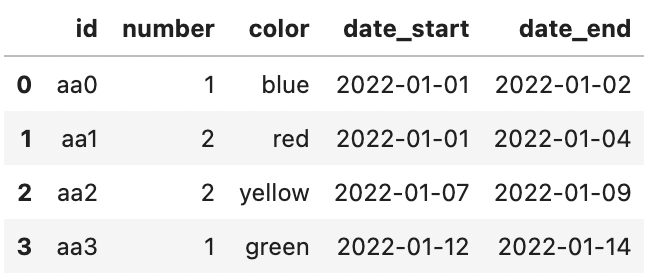
This gives the following result
Now to create a set containing all possible dates between the min and max date of the set:
df_d = pd.DataFrame({'date': pd.date_range(df['date_start'].min(), df['date_end'].max() pd.Timedelta('1d'), freq='1d')})
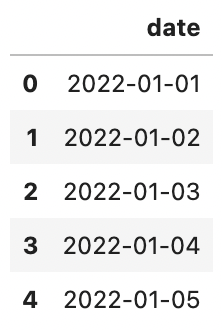
This results in an expected frame containing all the possible dates
Finally to cross merge the original set with the date set and filter resulting rows based on start and end date per row
df_total = pd.merge(df, df_d,how='cross')
df = df_total[(df_total['date_start']<df_total['date']) & (df_total['date_end']>=df_total['date']) ]
This leads to the following final
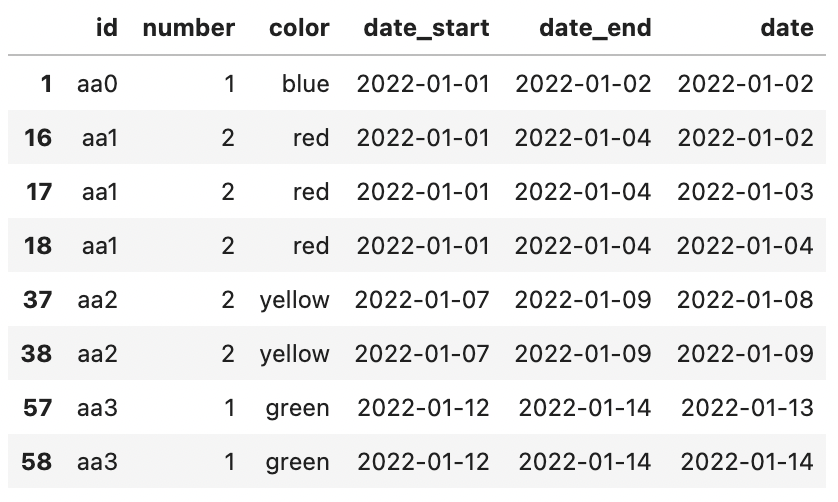
This final dataframe is exactly what is needed.
CodePudding user response:
Efficient Solution
d = df['date_end'].sub(df['date_start']).dt.days
df1 = df.reindex(df.index.repeat(d))
i = df1.groupby(level=0).cumcount() 1
df1['date'] = df1['date_start'] pd.to_timedelta(i, unit='d')
How it works?
Subtract start from end to calculate the number of days elapsed, then reindex the dataframe by repeating the index exactly elapsed number of days times. Now group df1 by index and use cumcount to create a sequential counter then create a timedelta series using this counter and add this with date_start to get the result
Result
id number color date_start date_end date
0 aa0 1 blue 2022-01-01 2022-01-02 2022-01-02
1 aa1 2 red 2022-01-01 2022-01-04 2022-01-02
1 aa1 2 red 2022-01-01 2022-01-04 2022-01-03
1 aa1 2 red 2022-01-01 2022-01-04 2022-01-04
2 aa2 2 yellow 2022-01-07 2022-01-09 2022-01-08
2 aa2 2 yellow 2022-01-07 2022-01-09 2022-01-09
3 aa3 1 green 2022-01-12 2022-01-14 2022-01-13
3 aa3 1 green 2022-01-12 2022-01-14 2022-01-14
CodePudding user response:
I don't know if this is an approvement, here the pd.date_range only gets created for each start and end date in each row. the created list gets exploded and joined to the original df
from datetime import date
import pandas as pd
raw_data = {'id': ['aa0', 'aa1', 'aa2', 'aa3'],
'number': [1, 2, 2, 1],
'color': ['blue', 'red', 'yellow', "green"],
'date_start': [date(2022,1,1), date(2022,1,1), date(2022,1,7), date(2022,1,12)],
'date_end': [date(2022,1,2), date(2022,1,4), date(2022,1,9), date(2022,1,14)]}
df = pd.DataFrame(raw_data)
s = df.apply(lambda x: pd.date_range(x['date_start'], x['date_end'], freq='1d',inclusive='right').date,axis=1).explode()
df.join(s.rename('date'))