Say I have just 2 columns in pandas. Column 1 has all numerical values and column 2 has values only at the every 16th position (so column 2 has value at index 0 followed by 15 NaN and value at index 16 followed by 15 NaNs).
How to create a new row, that contains itself and next 15 values of column 1 (as list [value, value2,....value16]) when column 2 is not null.
Can someone let me know a time efficient solution for the below:
Here is the pandas code to reproduce the sample data
df=pd.DataFrame(zip([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32],
['xyz',None,None,None,None,None,None,None,None,None,None,None,None,None,None,None,
'abc',None,None,None,None,None,None,None,None,None,None,None,None,None,None,None],
[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16],None,None,None,None,None,None,None,None,None,None,None,None,None,None,None,
[17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32],None,None,None,None,None,None,None,None,None,None,None,None,None,None,None]), columns= ['A','B','C'])
CodePudding user response:
Use a boolean mask:
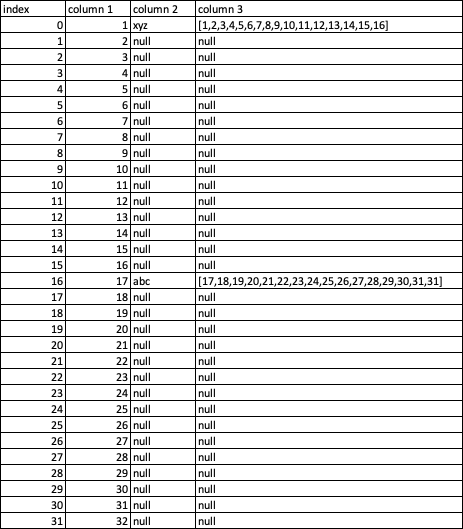
m = df['column 2'].notna()
df.loc[m, 'column 3'] = df.groupby(m.cumsum())['column 1'].agg(list).values
print(df)
# Output
column 1 column 2 column 3
0 1 xyz [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14...
1 2 NaN NaN
2 3 NaN NaN
3 4 NaN NaN
4 5 NaN NaN
5 6 NaN NaN
6 7 NaN NaN
7 8 NaN NaN
8 9 NaN NaN
9 10 NaN NaN
10 11 NaN NaN
11 12 NaN NaN
12 13 NaN NaN
13 14 NaN NaN
14 15 NaN NaN
15 16 NaN NaN
16 17 abc [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 2...
17 18 NaN NaN
18 19 NaN NaN
19 20 NaN NaN
20 21 NaN NaN
21 22 NaN NaN
22 23 NaN NaN
23 24 NaN NaN
24 25 NaN NaN
25 26 NaN NaN
26 27 NaN NaN
27 28 NaN NaN
28 29 NaN NaN
29 30 NaN NaN
30 31 NaN NaN
31 32 NaN NaN