I'm quite new to Pandas and I'm doing some work on concrete compressive strength. I have a dataset which I've imported into a dataframe like so:
file = "Concrete_Data.csv"
data = pd.read_csv(file)
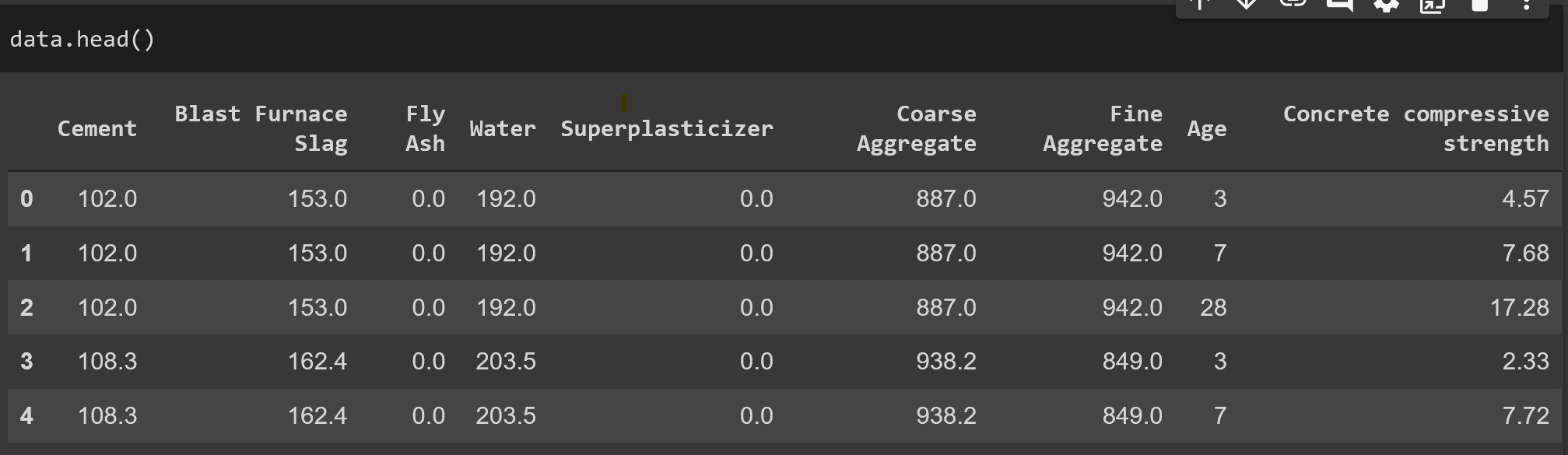
The dataset looks like this:
I then use the following code to create an additional column:
# insert water-cement ratio column
water_cement = pd.Series([])
for i in range(len(data)):
water_cement[i] = round(
data["Water"][i] / (data["Cement"][i] data["Water"][i]), 2)
data.insert(4, "Water-Cement", water_cement, True)
But before I do this, I want to filter down my dataframe to only records with 'Age' <= 28 and then operate on that dataset. I tried using this code:
data.query('Age <= 28', inline=True)
But then upon creating the water-cement column I hit KeyError: 222 - Can anyone explain this error and what's happening in the dataframe which is stopped the code from working?
CodePudding user response:
First filter:
data = data.query('Age <= 28')
Or:
data = data[data['Age'] <= 28]
and then use vectorized solution - divide and sum columns:
data.insert(4, "Water-Cement", (data["Water"] / (data["Cement"] data["Water"])).round(2))
CodePudding user response:
You have typo
data.query('Age <= 28', inline=True)
should be
data.query('Age <= 28', inplace=True)