I want to scrape 2015 from below HTML:
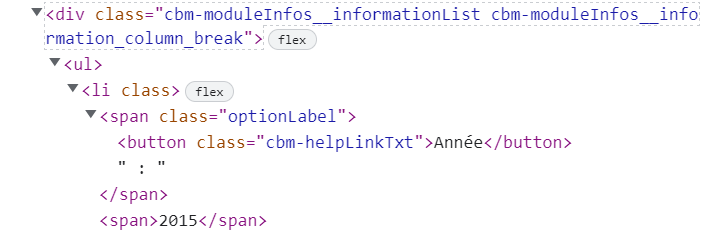
I use the below code but am only able to scrape "Annee"
soup.find('span', {'class':'optionLabel'}).get_text()
Can someone please help?
I am a new learner.
CodePudding user response:
Simply try to find its next span that holds the text you wanna scrape:
soup.find('span', {'class':'optionLabel'}).find_next('span').get_text()
or css selectors with adjacent sibling combinator:
soup.select_one('span.optionLabel span').get_text()
Example
html='''
<span ><button>Année</button</span> :
<span>2015</span>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
soup.find('span', {'class':'optionLabel'}).find_next('span').get_text()
Output
2015