I need to know the probability of selling similar items together, based on a sales history formatted like this:
pd.DataFrame({"sale_id": [1, 1, 1, 2, 2, 3, 3, 3, 3, 4],
"item": ["A", "B", "C", "A", "C", "A", "D", "E", "C", "B"],
"qty": [1, 4, 3, 2, 8, 3, 6, 5, 12, 9]})
sale_id Item Qty
1 A 1
1 B 4
1 C 3
2 A 2
2 C 8
3 A 3
3 D 6
3 E 5
3 C 12
4 B 9
I want to build a matrix like this:
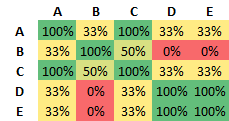
I have tried pivoting the data frame and using a the pd.DataFrame.corr() with a custom callable, but i ran out of RAM by calling:
pd.pivot_table(df, index = "sales_id", columns = "item")
The actual dataframe that I'm using is 700,000 lines long and have 20,000 different items.
CodePudding user response:
I believe the standard algorithm for collaborative filtering would go something like:
- first you need to group your data by sale_id and combine the values in the item column.
- Then for each group you need to create a set of items that were bought together.
- Then finally you need to create every possible combination of existing items as a set and do the intersection with your actual item sets
This is what it all looks for me. This should have a linear space complexity and I'm sure it can be improved still but it can work.
from itertools import combinations
import pandas as pd
df = pd.DataFrame({"sale_id": [1, 1, 1, 2, 2, 3, 3, 3, 3, 4],
"item": ["A", "B", "C", "A", "C", "A", "D", "E", "C", "B"],
"qty": [1, 4, 3, 2, 8, 3, 6, 5, 12, 9]})
# we don't care about quantity
df = df.loc[:, ['sale_id', 'item']]
# Get all the unique sets of items sold
grp = df.groupby('sale_id').transform(lambda x: ''.join(x))
purchases = grp['item'].apply(lambda x: ''.join(set(x))).unique()
# create all possible two-item pairs, then iterate over them
# adding 1 to the value of dictionary when the purchase
# matches the combination
unique_items = df.item.unique()
res = {}
for c in combinations(unique_items, 2):
c = set(c)
res[frozenset(c)] = 0
for i in purchases:
if c.intersection(i) == c:
res[frozenset(c)] = 1
# get percentages
for k, v in res.items():
res[k] = v / purchases.shape[0]
Output:
{frozenset({'A', 'B'}): 0.25,
frozenset({'A', 'C'}): 0.75,
frozenset({'A', 'D'}): 0.25,
frozenset({'A', 'E'}): 0.25,
frozenset({'B', 'C'}): 0.25,
frozenset({'B', 'D'}): 0.0,
frozenset({'B', 'E'}): 0.0,
frozenset({'C', 'D'}): 0.25,
frozenset({'C', 'E'}): 0.25,
frozenset({'D', 'E'}): 0.25}