I have a code that counts how many points there are for each quadrant of 10x10 and shows the result in each quadrant
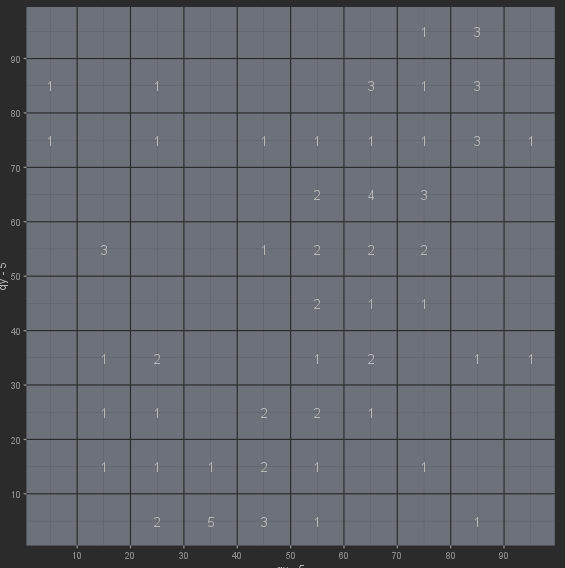
I have this Dataframe
qx qy n
<dbl> <dbl> <int>
1 10 80 1
2 10 90 1
3 20 20 1
4 20 30 1
5 20 40 1
6 20 60 3
7 30 10 2
8 30 20 1
9 30 30 1
10 30 40 2
# ... with 38 more rows
This is how I create the graph
ggplot()
scale_x_continuous(breaks = seq(0, 100, by = 10))
scale_y_continuous(breaks = seq(0, 100, by = 10))
geom_text(data=df, mapping=aes(x=qx-5, y=qy-5, label=n, size=1))
How can I add the missing quadrants to the dataframe?
missing quadrants:
10 10 0
20 10 0
70 10 0
...etc
CodePudding user response:
It might be easier to create a new empty data frame with all of the grid locations and then fill in with the known values.
See comments for the details:
library(dplyr)
#create default matrix with all grid locations
qx <- rep(seq(10, 90, 10), each=9)
qy <- rep(seq(10, 90, 10), 9)
empty <- data.frame(qx, qy)
data<- read.table(header=TRUE, text=" qx qy n
1 10 80 1
2 10 90 1
3 20 20 1
4 20 30 1
5 20 40 1
6 20 60 3
7 30 10 2
8 30 20 1
9 30 30 1
10 30 40 2")
#merge the known data with the master matrix
answer <-left_join(empty, data, by=c("qx"="qx", "qy"="qy"))
#replace NA with 0
answer$n[is.na(answer$n)] <-0
CodePudding user response:
Following the same logic as @Dave2e, I use tidyverse to first create a dataframe with all of the combinations for the grid locations, then join the data, replace the NA values with 0, then plot. Since I'm only using a subset of the data, then the values won't be the same as the grid in your question.
library(tidyverse)
crossing(qx = seq(10, 100, 10), qy = seq(10, 100, 10)) %>%
left_join(., df, by = c("qx", "qy")) %>%
mutate(n = replace_na(n, 0)) %>%
ggplot(.)
scale_x_continuous(breaks = seq(0, 100, by = 10))
scale_y_continuous(breaks = seq(0, 100, by = 10))
geom_text(mapping = aes(x = qx - 5, y = qy - 5, label = n, size = 1))
Output
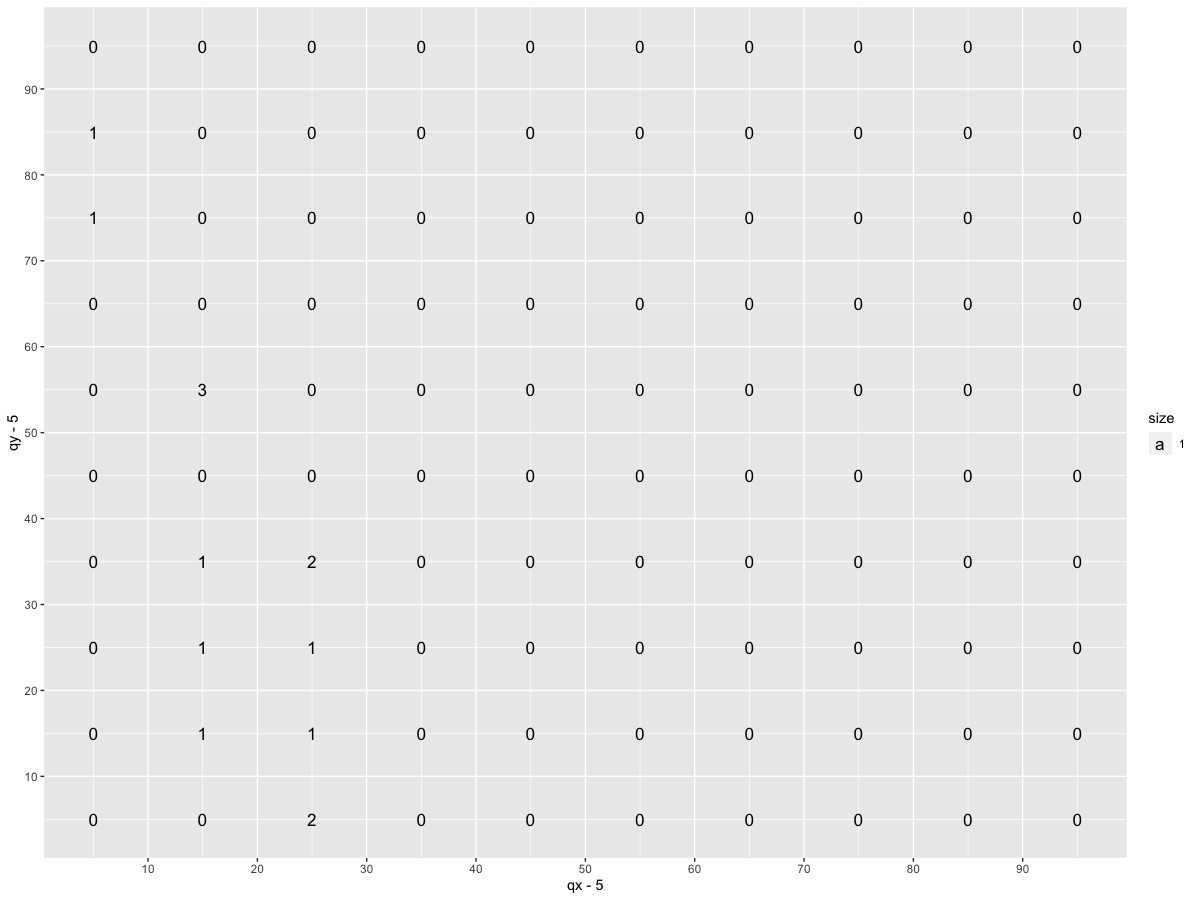
Data
df <- structure(list(qx = c(10L, 10L, 20L, 20L, 20L, 20L, 30L, 30L,
30L, 30L), qy = c(80L, 90L, 20L, 30L, 40L, 60L, 10L, 20L, 30L,
40L), n = c(1L, 1L, 1L, 1L, 1L, 3L, 2L, 1L, 1L, 2L)), class = "data.frame", row.names = c("1",
"2", "3", "4", "5", "6", "7", "8", "9", "10"))