I am using logistic regression for a football dataset, but it seems when i try to one-hot encode the home team names and away team names it gives the model a 100% accuracy, even when doing a train_test_split i still get 100. What am i doing wrong?
from sklearn.linear_model
import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
import numpy as np
df = pd.read_csv("FIN.csv")
df['Date'] = pd.to_datetime(df["Date"])
df = df[(df["Date"] > '2020/04/01')]
df['BTTS'] = np.where((df.HG > 0) & (df.AG > 0), 1, 0)
#print(df.to_string())
df.dropna(inplace=True)
x = df[['Home', 'Away', 'Res', 'HG', 'AG', 'PH', 'PD', 'PA', 'MaxH', 'MaxD', 'MaxA', 'AvgH', 'AvgD', 'AvgA']].values
y = df['BTTS'].values
np.set_printoptions(threshold=np.inf)
model = LogisticRegression()
ohe = OneHotEncoder(categories=[df.Home, df.Away, df.Res], sparse=False)
x = ohe.fit_transform(x)
print(x)
model.fit(x, y)
print(model.score(x, y))
x_train, x_test, y_train, y_test = train_test_split(x, y, shuffle=False)
model.fit(x_train, y_train)
print(model.score(x_test, y_test))
y_pred = model.predict(x_test)
print("accuracy:",
accuracy_score(y_test, y_pred))
print("precision:", precision_score(y_test, y_pred))
print("recall:", recall_score(y_test, y_pred))
print("f1 score:", f1_score(y_test, y_pred))
CodePudding user response:
Overfitting would be a situation where your training accuracy is very high, and your test accuracy is very low. That means it's "over fitting" because it essentially just learns what the outcome will be on the training, but doesn't fit well on new, unseen data.
The reason you are getting 100% accuracy is precisely as I stated in the comments, there's a (for lack of a better term) data leakage. You are essentially allowing your model to "cheat". Your target variable y (which is 'BTTS') is feature engineered by the data. It is derived from 'HG' and 'AG', and thus are highly (100%) correlated/associated to your target. You define 'BTTS' as 1 when both 'HG' and 'AG' are greater than 1. And then you have those 2 columns included in your training data. So the model simply picked up that obvious association (Ie, when the home goals is 1 or more, and the away goals are 1 or more -> Both teams scored).
Once the model sees those 2 values greater than 0, it predicts 1, if one of those values is 0, it predicts 0.
Drop 'HG' and 'AG' from the x (features).
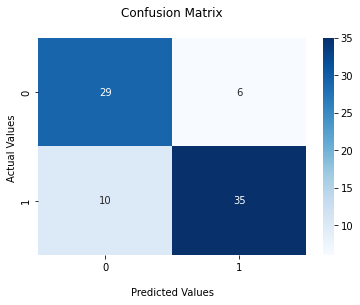
Once we remove those 2 columns, you'll see a more realistic performance (albeit poor - slightly better than a flip of the coin) here:
1.0
0.5625
accuracy: 0.5625
precision: 0.6666666666666666
recall: 0.4444444444444444
f1 score: 0.5333333333333333
With the Confusion Matrix:
from sklearn.metrics import confusion_matrix
labels = labels = np.unique(y).tolist()
cf_matrixGNB = confusion_matrix(y_test, y_pred, labels=labels)
import seaborn as sns
import matplotlib.pyplot as plt
ax = sns.heatmap(cf_matrixGNB, annot=True,
cmap='Blues')
ax.set_title('Confusion Matrix\n');
ax.set_xlabel('\nPredicted Values')
ax.set_ylabel('Actual Values ');
ax.xaxis.set_ticklabels(labels)
ax.yaxis.set_ticklabels(labels)
plt.show()
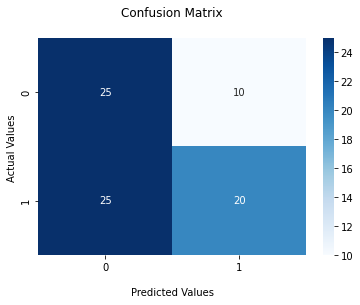
Another option would be to do a calculated field of 'Total_Goals', then see if it can predict on that. Obviously again, it has a little help in the obvious (if 'Total_Goals' is 0 or 1, then 'BTTS' will be 0.). But then if 'Total_Goals' is 2 or more, it'll have to rely on the other features to try to work out if one of the teams got shut out.
Here's that example:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
import numpy as np
df = pd.read_csv("FIN.csv")
df['Date'] = pd.to_datetime(df["Date"])
df = df[(df["Date"] > '2020/04/01')]
df['BTTS'] = np.where((df.HG > 0) & (df.AG > 0), 1, 0)
#print(df.to_string())
df.dropna(inplace=True)
df['Total_Goals'] = df['HG'] df['AG']
x = df[['Home', 'Away', 'Res', 'Total_Goals', 'PH', 'PD', 'PA', 'MaxH', 'MaxD', 'MaxA', 'AvgH', 'AvgD', 'AvgA']].values
y = df['BTTS'].values
np.set_printoptions(threshold=np.inf)
model = LogisticRegression()
ohe = OneHotEncoder(sparse=False)
x = ohe.fit_transform(x)
#print(x)
model.fit(x, y)
print(model.score(x, y))
x_train, x_test, y_train, y_test = train_test_split(x, y, shuffle=False)
model.fit(x_train, y_train)
print(model.score(x_test, y_test))
y_pred = model.predict(x_test)
print("accuracy:",
accuracy_score(y_test, y_pred))
print("precision:", precision_score(y_test, y_pred))
print("recall:", recall_score(y_test, y_pred))
print("f1 score:", f1_score(y_test, y_pred))
from sklearn.metrics import confusion_matrix
labels = np.unique(y).tolist()
cf_matrixGNB = confusion_matrix(y_test, y_pred, labels=labels)
import seaborn as sns
import matplotlib.pyplot as plt
ax = sns.heatmap(cf_matrixGNB, annot=True,
cmap='Blues')
ax.set_title('Confusion Matrix\n');
ax.set_xlabel('\nPredicted Values')
ax.set_ylabel('Actual Values ');
ax.xaxis.set_ticklabels(labels)
ax.yaxis.set_ticklabels(labels)
plt.show()
Output:
1.0
0.8
accuracy: 0.8
precision: 0.8536585365853658
recall: 0.7777777777777778
f1 score: 0.8139534883720929