I'm trying to achieve something with pandas which is very straightforward to do in Excel PivotTable:
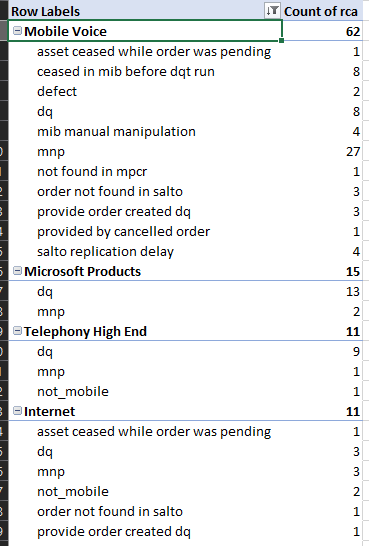
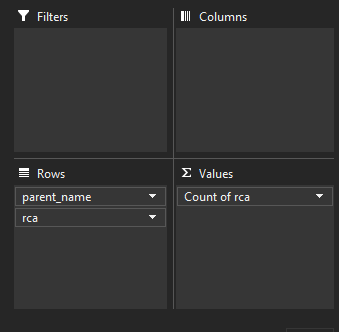
From what I've seen, the following code seems logic, but it doesn't work. And bottom line I'm wondering how complex can it get to implement such a simple aggregation. Any suggestions?
pt = pd.pivot_table(data=df,
aggfunc = 'count',
index = ["root_name", "rca"],
values = ["rca"],
margins = True).sort_values(['rca'],
ascending=[False])
EDIT: Sample input data and output
try: from io import StringIO # Python 3
except: from StringIO import StringIO # Python 2
import pandas as pd
TESTDATA = u"""root_name;rca
Mobile Voice;mib manual manipulation
Mobile Voice;mib manual manipulation
Internet;dq
Mobile Voice;defect
Internet;mnp
Mobile Voice;mnp
Mobile Voice;defect
Mobile Voice;ceased in mib before dqt run
Mobile Voice;mnp
Mobile Voice;ceased in mib before dqt run
Internet;dq
Mobile Voice;mnp
Mobile Voice;dq
Mobile Voice;no dq
Mobile Voice;no dq
Mobile Voice;asset ceased while order was pending
Internet;dq
Mobile Voice;no dq
Internet;mnp
Mobile Voice;mnp
Mobile Voice;salto replication delay
Mobile Voice;provide order created dq
Internet;mnp
Mobile Voice;mib manual manipulation
Mobile Voice;mnp
Mobile Voice;mnp
Mobile Voice;ceased in mib before dqt run
Mobile Voice;mnp
Mobile Voice;mib manual manipulation
"""
df = pd.read_csv(StringIO(TESTDATA), sep=';', usecols= ['root_name', 'rca'], engine='python')
pt = pd.pivot_table(data=df,
aggfunc = 'count',
index = ["root_name", "rca"],
values = ["rca"],
margins = True)
print (pt.sort_values(['rca'],
ascending=[False]))
Result: Empty DataFrame Columns: [] Index: [(Mobile Voice, salto replication delay), (Mobile Voice, provide order created dq), (Mobile Voice, no dq), (Internet, mnp), (Mobile Voice, mnp), (Mobile Voice, mib manual manipulation), (Internet, dq), (Mobile Voice, dq), (Mobile Voice, defect), (Mobile Voice, ceased in mib before dqt run), (Mobile Voice, asset ceased while order was pending), (All, )]
CodePudding user response:
Try to add 'count' field to your data frame and then just group by using count() method:
df['count'] = 1
df.groupby(by=['root_name', 'rca']).count().sort_index('rca')
Output:
count
root_name rca
Internet dq 3
mnp 3
Mobile Voice asset ceased while order was pending 1
ceased in mib before dqt run 3
defect 2
dq 1
mib manual manipulation 4
mnp 7
no dq 3
provide order created dq 1
salto replication delay 1
Small tweak to reproduce excel results, by adding "root_name" sum field:
grouped_sum = df.groupby(by='root_name').sum().reset_index(level=[0])
grouped = df.merge(grouped_sum, how='left', on='root_name')
grouped.rename(columns={'count_x': 'count', 'count_y': 'sum'}, inplace=True)
grouped
root_name rca count sum
0 Mobile Voice mib manual manipulation 1 23
1 Mobile Voice mib manual manipulation 1 23
2 Internet dq 1 6
pd.pivot_table(
data=grouped,
aggfunc=['count'],
index=[ "root_name", "sum", "rca"],
values=["count"],
margins=True).sort_values(["sum", 'root_name', 'rca'],
ascending=[False, True, True]
)
Output:
count
count
root_name sum rca
All 29
Mobile Voice 23 asset ceased while order was pending 1
ceased in mib before dqt run 3
defect 2
dq 1
mib manual manipulation 4
mnp 7
no dq 3
provide order created dq 1
salto replication delay 1
Internet 6 dq 3
mnp 3