Following on from my previous question (thanks to those responding) I'm stuck again in achieving what I suspect is possible using a groupby in Pandas. Here's what I'm trying to achieve. With the following example dataframe:
data_initial = {
"account_id": ['1001', '1001', '1001', '1002', '1002', '1002', '1002', '1002', '1002', '1002', '1002', '1002', '1002', '1003', '1003', '1003', '1003', '1003', '1003',],
"data_type": ['payment', 'payment', 'payment', 'payment', 'payment', 'plan', 'payment', 'plan', 'plan', 'payment', 'payment', 'payment', 'payment', 'payment', 'plan', 'payment', 'payment', 'payment', 'payment',],
"transaction_date": ['2022-04-01', '2022-04-12', '2022-05-02', '2022-02-02', '2022-03-01', '2022-03-15', '2022-04-01', '2022-04-01', '2022-04-13', '2022-04-26', '2022-05-01', '2022-05-04', '2022-05-10', '2022-03-10', '2022-03-25', '2022-04-05', '2022-04-16', '2022-04-24', '2022-05-05',],
"amount": ['-50', '-40', '-60', '-30', '-25', '250', '-50', '200', '200', '-25', '-25', '-25', '-25', '-20', '100', '-25', '-25', '-25', '-25',],}
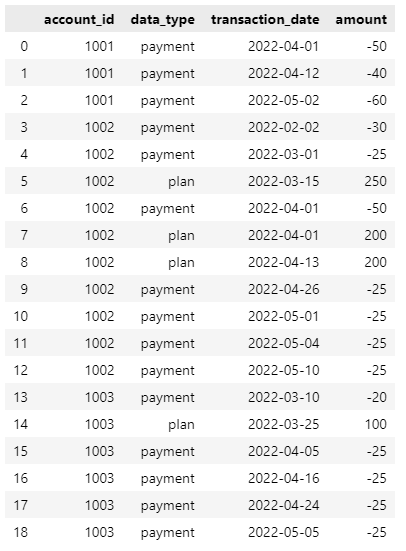
I'm looking to, effectively, groupby the account_id and then apply the following logic:
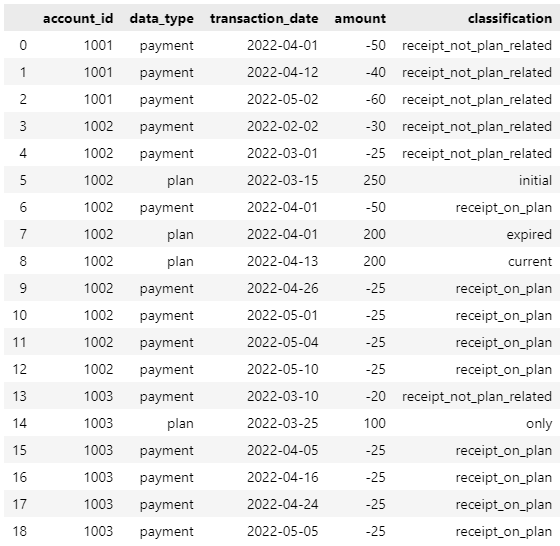
IF
data_typeis "payment" AND {account_idhas nodata_type= "plan" OR thetransaction_dateof the record is BEFORE anydata_type= "plan" record} then new columnclassification= "receipt_not_plan_related"IF
data_typeis "payment" AND {account_idhas adata_type= "plan" ANDtransaction_dateis AFTER anydata_type= "plan" record} then new columnclassification= "receipt_on_plan"IF
data_typeis "plan" is the only instance of "plan" then new columnclassification= "only"IF
data_typeis "plan" AND is the FIRST instance of "plan" then new columnclassification= "initial"IF
data_typeis "plan" AND is NOT the FIRST and NOT the LAST instance of "plan" then new columnclassification= "expired"IF
data_typeis "plan" AND is the LAST instance of "plan" then new columnclassification= "current"
The result, therefore, for the example dataframe would be as follows:
Thanks again, in advance, to anyone who can help out. Much appreciated.
CodePudding user response:
You can do it with np.select and a couple of helper columns:
import numpy as np
df['plans'] = df.groupby('account_id')['data_type'].transform(lambda x: x.eq('plan').cumsum())
df['n_plans'] = df.groupby('account_id')['plans'].transform('max')
is_payment = df['data_type'].eq('payment')
is_plan = df['data_type'].eq('plan')
df['classification'] = np.select([is_payment & df['plans'].eq(0),
is_payment & df['plans'].gt(0),
is_plan & df['n_plans'].eq(1),
is_plan & df['plans'].eq(1),
is_plan & df['plans'].gt(1) & df['plans'].lt(df['n_plans']),
is_plan & df['plans'].eq(df['n_plans'])],
['receipt_not_plan_related',
'receipt_on_plan',
'only',
'initial',
'expired',
'current'])
print(df.drop(columns=['plans', 'n_plans']))
account_id data_type transaction_date amount classification
0 1001 payment 2022-04-01 -50 receipt_not_plan_related
1 1001 payment 2022-04-12 -40 receipt_not_plan_related
2 1001 payment 2022-05-02 -60 receipt_not_plan_related
3 1002 payment 2022-02-02 -30 receipt_not_plan_related
4 1002 payment 2022-03-01 -25 receipt_not_plan_related
5 1002 plan 2022-03-15 250 initial
6 1002 payment 2022-04-01 -50 receipt_on_plan
7 1002 plan 2022-04-01 200 expired
8 1002 plan 2022-04-13 200 current
9 1002 payment 2022-04-26 -25 receipt_on_plan
10 1002 payment 2022-05-01 -25 receipt_on_plan
11 1002 payment 2022-05-04 -25 receipt_on_plan
12 1002 payment 2022-05-10 -25 receipt_on_plan
13 1003 payment 2022-03-10 -20 receipt_not_plan_related
14 1003 plan 2022-03-25 100 only
15 1003 payment 2022-04-05 -25 receipt_on_plan
16 1003 payment 2022-04-16 -25 receipt_on_plan
17 1003 payment 2022-04-24 -25 receipt_on_plan
18 1003 payment 2022-05-05 -25 receipt_on_plan
Note that the records need to be sorted by 'transaction_date' in ascending order within each 'account_id' for this to work, since the "before", "first" and "last" conditions are checked using GroupBy.transform() that calculates a cumulative sum.