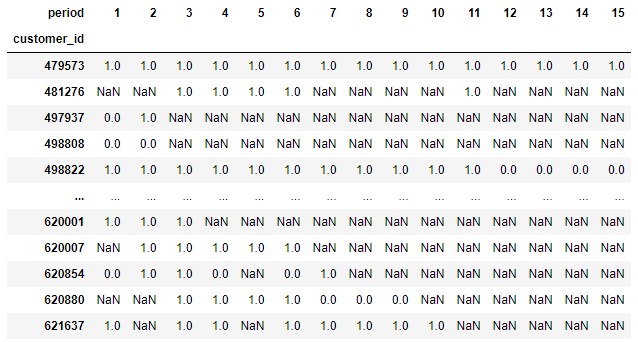
I have the following data (see attached - easier this way). I am trying to find the first occurrence of the value 0 for each customer ID. Then, I plan to use code similar to below to create a Kaplan-Meier curve:
from lifelines import KaplanMeierFitter
## Example Data
durations = [5,6,6,2.5,4,4]
event_observed = [1, 0, 0, 1, 1, 1]
## create a kmf object
kmf = KaplanMeierFitter()
## Fit the data into the model
kmf.fit(durations, event_observed,label='Kaplan Meier Estimate')
## Create an estimate
kmf.plot(ci_show=False) ## ci_show is meant for Confidence interval, since our data set is too tiny, thus i am not showing it.
(this code is from here).
What' the simplest way to do this? Note that I want to ignore the NAs: I have plenty of them and there's no getting around that.
Thanks!
CodePudding user response:
I'm gonna assume that all rows contain at least one non-NaN value.
One thing we'd have to do first is just ensure that we operate on a dataframe where there is indeed a zero; we can accomplish this with min.
This will give us a series, and we just have to select on the rows that contain zero:
df.loc[min_series == 0]
Then, we can use idxmin:
df.idxmin(1, skipna=True)
This should spit out the period on which the first 0 is encountered (we've guaranteed that all rows contain a 0).
Then, this should give you what you're looking for!