I'm trying to get None if the class is not found in web scraping. For example, in some cases stage-codes.html#10_99 doesn't exist in HTML.
for st in soup.find_all("ul", {"class": "dropdown-menu"}):
for k in st.find_all("a", {"href": "/stage-codes.html#10_99"},limit=1):
a = k.find("span", class_='stage-date').getText()
print(a)
try:
start_date.append(a)
except:
start_date.append(None)
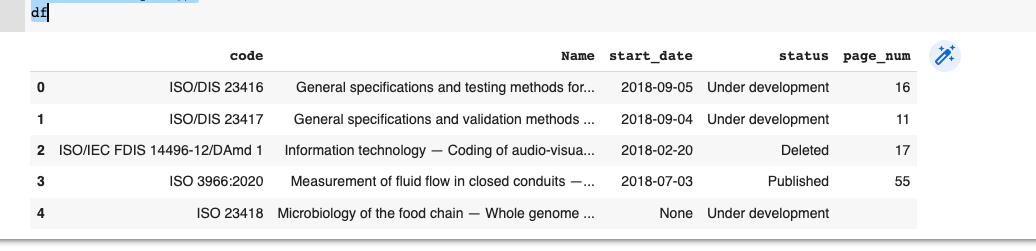
The 3rd index's start_date must be None instead of data of 4th index:
CodePudding user response:
According to the docs, If find() can’t find anything, it returns None
So, assuming there's not an error in how you're setting up your for loops, you should be able to try something link this:
for st in soup.find_all("ul", {"class": "dropdown-menu"}):
for k in st.find_all("a", {"href": "/stage-codes.html#10_99"},limit=1):
a = k.find("span", class_='stage-date')
try:
a_text = a.get_text()
print(a_text)
start_date.append(a_text)
except:
start_date.append(None)
But since nothing is getting appended at this point then I would say one of your loops isn't getting triggered at all
CodePudding user response:
You put limit=1 so if /stage-codes.html#10_99 is found, the length of x here will be 1. You can check that with an if statement. Also, I believe None should be a string.
for st in soup.find_all("ul", class_= "dropdown-menu"):
x = st.find_all('a', href="/stage-codes.html#10_99", limit=1)
if len(x) == 1:
for k in x:
a = k.find("span", class_='stage-date').getText()
print(a)
start_date.append(a)
else:
start_date.append("None")