Given two monthly time series data sample from 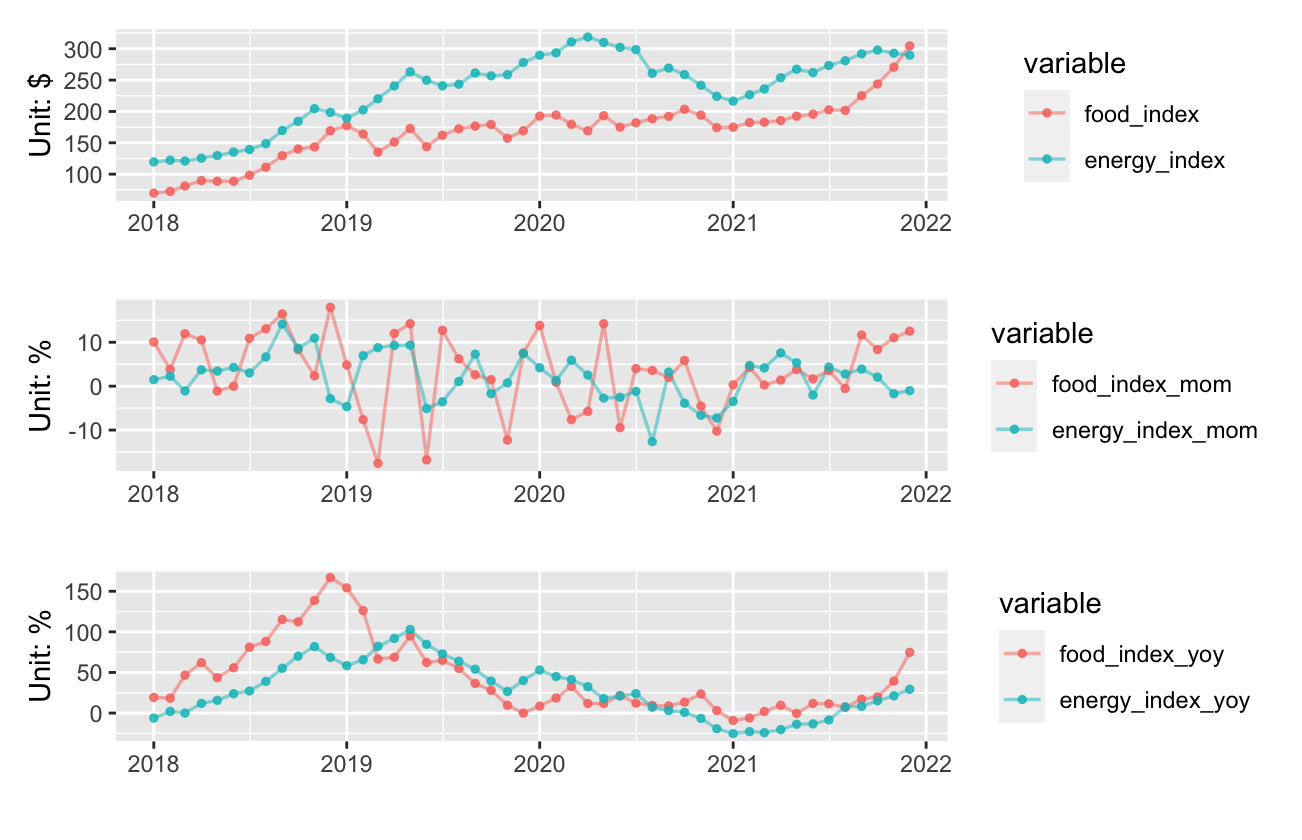
The expected result will be similar to the plot below (the upper plot will display the original data, the middle plot will display the mom changes data, and the lower plot will display the yoy changes data):
References:
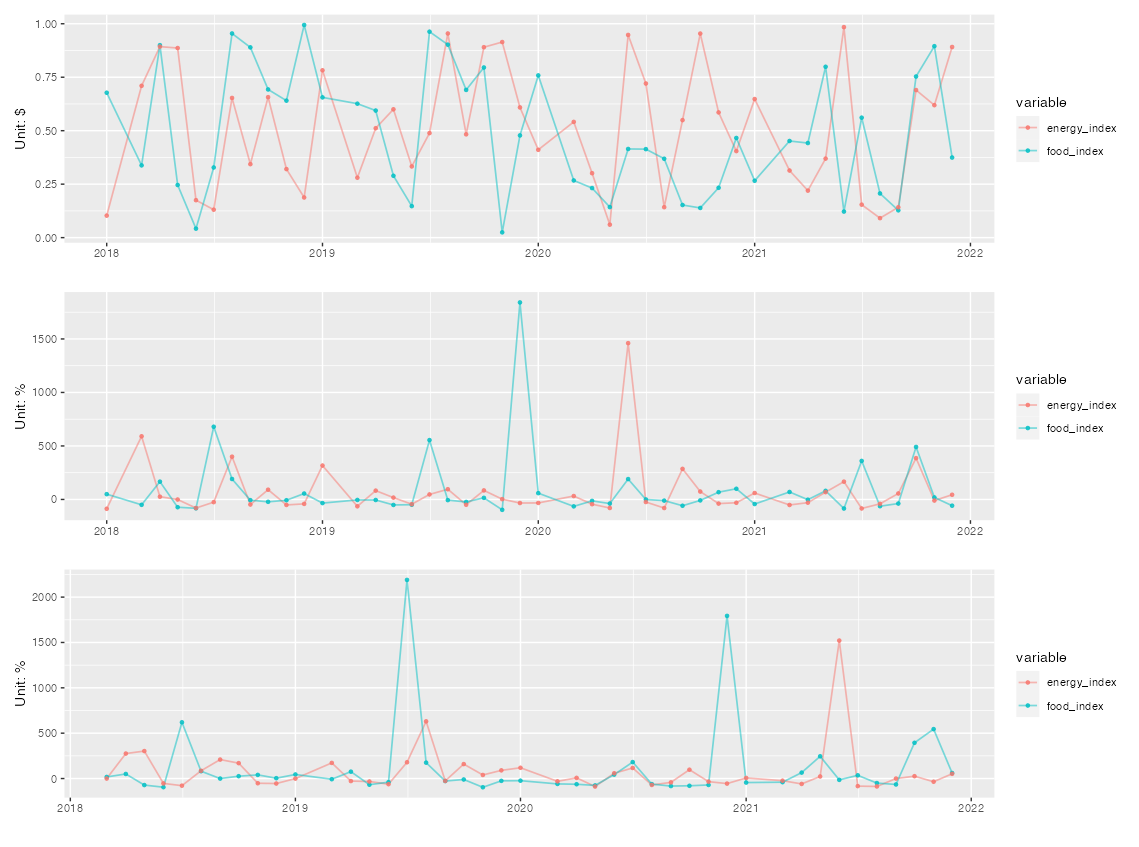
DATA
set.seed(123)
date <- seq.POSIXt(as.POSIXct("2017-01-31"), as.POSIXct("2022-12-31"), by = "month")
food_index <- runif(length(date))
energy_index <- runif(length(date))
df <- data.frame(date, food_index, energy_index)
EDIT Adding subtitles to each plot when using patchwork is (as of the moment) a bit tricky. What I would do in this case would be to use a faceting "hack". To this end I slightly adjusted the function to take a subtitle argument and switched to purrr::pmap:
library(tidyr)
library(dplyr)
library(ggplot2)
df_long <- df |>
rename(food_index_raw = food_index, energy_index_raw = energy_index) |>
pivot_longer(-date, names_to = c("variable", ".value"), names_pattern = "^(.*?_index)_(.*)$")
plot_fun <- function(x, y, ylab, subtitle) {
x <- x |>
select(date, variable, value = .data[[y]]) |>
filter(!is.na(value))
ggplot(
x,
aes(
x = date,
y = value,
col = variable
)
)
geom_line(size = 0.6, alpha = 0.5)
geom_point(size = 1, alpha = 0.8)
facet_wrap(~.env$subtitle)
labs(
x = "",
y = ylab
)
theme(strip.background = element_blank(), strip.text.x = element_text(hjust = 0))
}
yvars <- c("raw", "mom", "yoy")
ylabs <- paste0("Unit: ", c("$", "%", "%"))
subtitle <- c("Original", "Month-to-Month", "Year-to-Year")
plots <- purrr::pmap(list(y = yvars, ylab = ylabs, subtitle = subtitle), plot_fun, x = df_long)
library(patchwork)
wrap_plots(plots) plot_layout(ncol = 1)
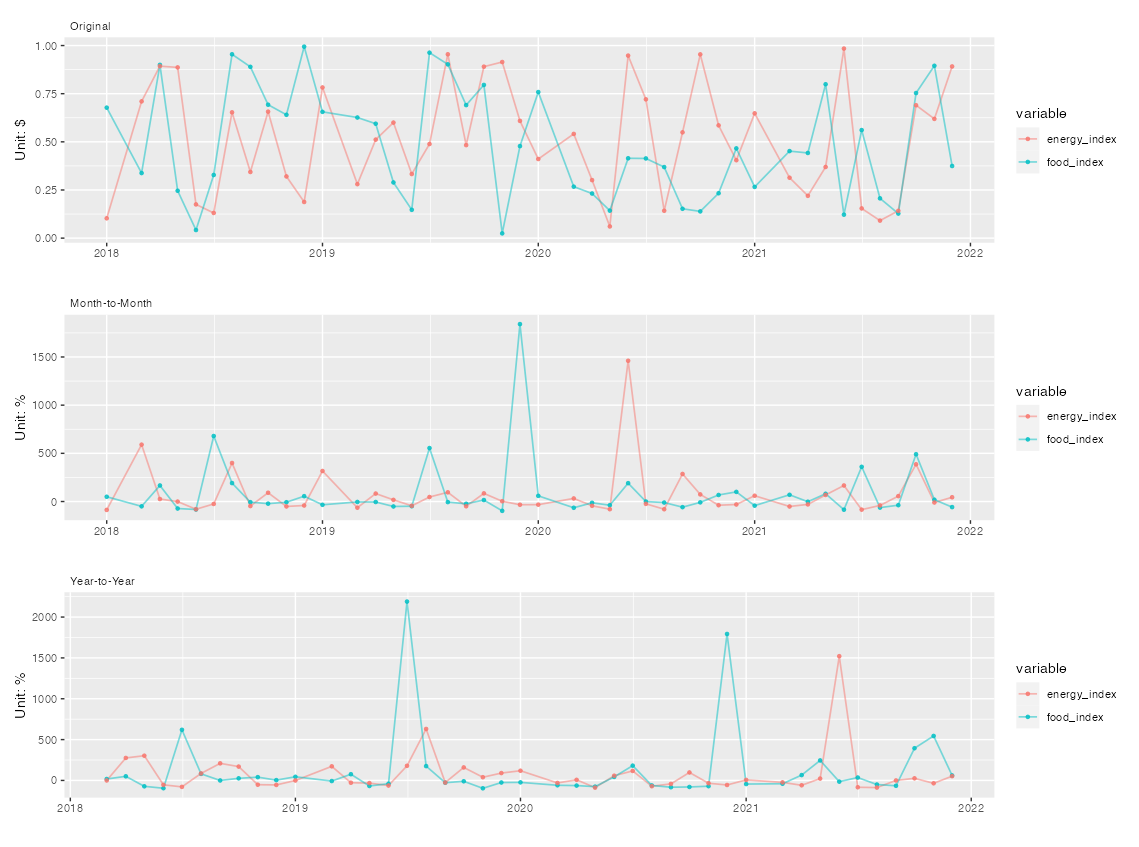
CodePudding user response:
The target output is done with facets rather than stitching plots together. You could do this too if you like, but it requires reshaping your data in a different way. Which approach you take is really a matter of taste.
library(ggplot2)
library(dplyr)
yoy <- function(x) 100 * (x - lag(x, 13)) / lag(x, 12)
mom <- function(x) 100 * (x - lag(x)) / lag(x)
df %>%
mutate(date = as.Date(date, origin = "1899-12-30"),
`Actual value (Dollars).Food Index` = food_index,
`Month-on-month change (%).Food Index` = mom(food_index),
`Year-on-year change (%).Food Index` = yoy(food_index),
`Actual value (Dollars).Energy Index` = energy_index,
`Month-on-month change (%).Energy Index` = mom(energy_index),
`Year-on-year change (%).Energy Index` = yoy(energy_index)) %>%
select(-food_index, -energy_index) %>%
tidyr::pivot_longer(-1) %>%
filter(date > as.Date("2018-01-01")) %>%
tidyr::separate(name, into = c("series", "index"), sep = "\\.") %>%
ggplot(aes(date, value, color = index))
geom_point(na.rm = TRUE)
geom_line()
facet_grid(series~., scales = "free_y")
theme_bw(base_size = 16)
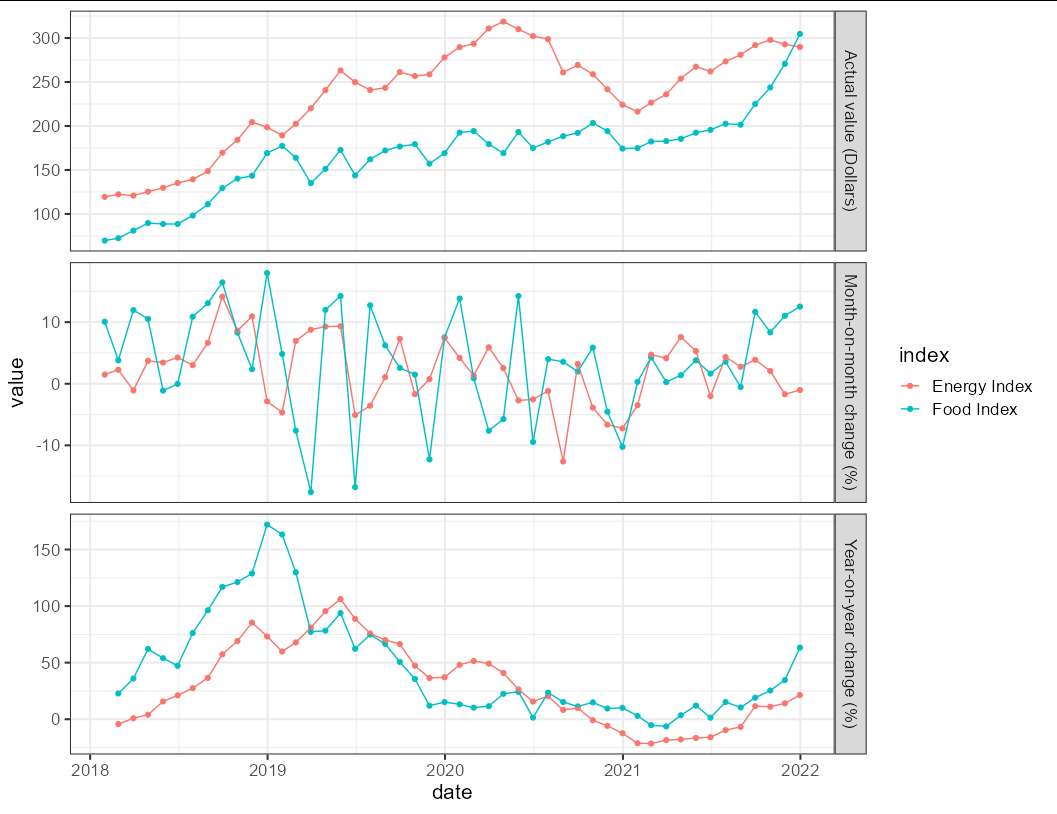
Reproducible data taken from link in question
df <- structure(list(date = c(42766, 42794, 42825, 42855, 42886, 42916,
42947, 42978, 43008, 43039, 43069, 43100, 43131, 43159, 43190,
43220, 43251, 43281, 43312, 43343, 43373, 43404, 43434, 43465,
43496, 43524, 43555, 43585, 43616, 43646, 43677, 43708, 43738,
43769, 43799, 43830, 43861, 43890, 43921, 43951, 43982, 44012,
44043, 44074, 44104, 44135, 44165, 44196, 44227, 44255, 44286,
44316, 44347, 44377, 44408, 44439, 44469, 44500, 44530, 44561
), food_index = c(58.53, 61.23, 55.32, 55.34, 61.73, 56.91, 54.27,
59.08, 60.11, 66.01, 60.11, 63.41, 69.8, 72.45, 81.11, 89.64,
88.64, 88.62, 98.27, 111.11, 129.39, 140.14, 143.44, 169.21,
177.39, 163.88, 135.07, 151.28, 172.81, 143.82, 162.13, 172.22,
176.67, 179.3, 157.27, 169.12, 192.51, 194.2, 179.4, 169.1, 193.17,
174.92, 181.92, 188.41, 192.14, 203.41, 194.19, 174.3, 174.86,
182.33, 182.82, 185.36, 192.41, 195.59, 202.6, 201.51, 225.01,
243.78, 270.67, 304.57), energy_index = c(127.36, 119.87, 120.96,
112.09, 112.19, 109.24, 109.56, 106.89, 109.35, 108.35, 112.39,
117.77, 119.52, 122.24, 120.91, 125.41, 129.72, 135.25, 139.33,
148.6, 169.62, 184.23, 204.38, 198.55, 189.29, 202.47, 220.23,
240.67, 263.12, 249.74, 240.84, 243.42, 261.2, 256.76, 258.69,
277.98, 289.63, 293.46, 310.81, 318.68, 310.04, 302.17, 298.62,
260.92, 269.29, 258.84, 241.68, 224.18, 216.36, 226.57, 235.98,
253.86, 267.37, 261.99, 273.37, 280.91, 291.84, 297.88, 292.78,
289.79)), row.names = c(NA, 60L), class = "data.frame")