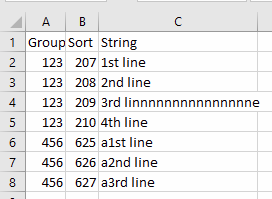
In writing dataframe to Excel spreadsheet, I want the file to have no border on the first row and column width to be auto adjusted.
With the old package xlwt and xlrd, I can read the file from Pandas produced, to a new file with no border on the header. But it's .xls (not .xlsx) format.
I can't make the column width auto adjusted (according to the content of the cells).
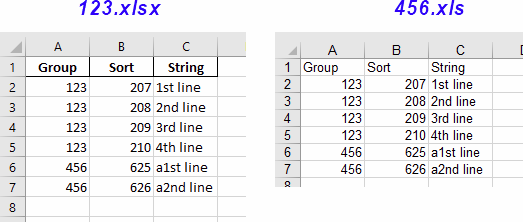
The lines looked tedious and troublesome.
What would be the Pandas way to do so? Thank you.
import pandas as pd
from io import StringIO
csvfile = StringIO(
"""Group Sort String
123 207 1st line
123 208 2nd line
123 209 3rd line
123 210 4th line
456 625 a1st line
456 626 a2nd line
456 627 a3rd line
""")
df = pd.read_csv(csvfile, sep = '\t', engine='python')
df.to_excel("C:\\TEM\\123.xlsx", index = False)
from xlwt import Workbook,easyxf,Formula
import xlrd
import xlwt
import xlsxwriter
from xlrd import open_workbook
style = easyxf('borders: left no_line, right no_line, top no_line, bottom no_line;')
old_file = open_workbook("C:\\TEM\\123.xlsx")
old_sheet = old_file.sheet_by_index(0)
new_file = xlwt.Workbook(encoding='utf-8', style_compression = 0)
new_sheet = new_file.add_sheet('Sheet1', cell_overwrite_ok = True)
row_data = []
for row_index in range(old_sheet.nrows):
rows = old_sheet.row_values(row_index)
row_data.append(rows)
for row_index, row in enumerate(row_data):
for col_index, cell_value in enumerate(row):
new_sheet.write(row_index, col_index, cell_value, style)
new_file.save('C:\\TEM\\456.xls')
CodePudding user response:
For the first question, use:
df.T.reset_index().T
Demonstration:
df.to_excel('test1.xlsx', index=None)
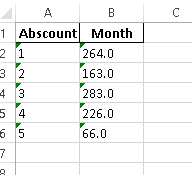
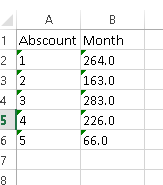
df.T.reset_index().T.to_excel('test2.xlsx', header=None, index=None)
CodePudding user response:
Posting the full code, inspired Keramat, and Giorgos Myrianthous's answer to