Here is my example data with two fields where the last one [outbreak] is a pandas series.
Start:

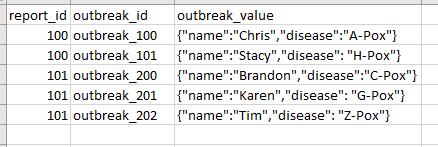
Goal (Excel mock-up):
Reproduction Code:
import pandas as pd
import json
d = {'report_id': [100, 101], 'outbreak': [
'{"outbreak_100":{"name":"Chris","disease":"A-Pox"},"outbreak_101":{"name":"Stacy","disease": "H-Pox"}}',
'{"outbreak_200":{"name":"Brandon","disease":"C-Pox"},"outbreak_201":{"name":"Karen","disease": "G-Pox"},"outbreak_202":{"name":"Tim","disease": "Z-Pox"}}']}
df = pd.DataFrame(data=d)
print(type(df['outbreak']))
display(df)
#Ignore
df = pd.json_normalize(df['outbreak'].apply(json.loads), max_level=0)
display(df)
Attempts: I thought about using json_normalize() which would convert every [outbreak_id] to its own field and then use pandas.wide_to_long() to get my final output. It works in testing but my concern is that my actual production data is so long and nested that it ends up generating hundred of thousands of fields before pivoting. That does not sounds good to me and why I also hope to avoid loop iterations.
I also thought about using df = df.explode('outbreak') but I am getting a KeyError: 0
Perhaps someone has a better idea than I do? Thank you.
CodePudding user response:
You can try with ast convert to dict format , then we do conversion
import ast
out = df.pop('outbreak').map(ast.literal_eval).apply(pd.Series).stack().reset_index(level=1).join(df)
out.columns = ['outbreak_id','outbreak_value','report_id']
Out[157]:
level_1 0 report_id
0 outbreak_100 {'name': 'Chris', 'disease': 'A-Pox'} 100
0 outbreak_101 {'name': 'Stacy', 'disease': 'H-Pox'} 100
1 outbreak_200 {'name': 'Brandon', 'disease': 'C-Pox'} 101
1 outbreak_201 {'name': 'Karen', 'disease': 'G-Pox'} 101
1 outbreak_202 {'name': 'Tim', 'disease': 'Z-Pox'} 101
CodePudding user response:
Try this
import json
d = {'report_id': [100, 101], 'outbreak': [
'{"outbreak_100":{"name":"Chris","disease":"A-Pox"},"outbreak_101":{"name":"Stacy","disease": "H-Pox"}}',
'{"outbreak_200":{"name":"Brandon","disease":"C-Pox"},"outbreak_201":{"name":"Karen","disease": "G-Pox"},"outbreak_202":{"name":"Tim","disease": "Z-Pox"}}']}
df = pd.DataFrame(data=d)
# use json.loads to parse the json and construct df from it
df = pd.DataFrame(df.set_index('report_id')['outbreak'].map(json.loads).to_dict()).stack().rename_axis(['outbreak_id', 'report_id'], axis=0).reset_index(name='outbreak_value')
print(df)
outbreak_id report_id outbreak_value
0 outbreak_100 100 {'name': 'Chris', 'disease': 'A-Pox'}
1 outbreak_101 100 {'name': 'Stacy', 'disease': 'H-Pox'}
2 outbreak_200 101 {'name': 'Brandon', 'disease': 'C-Pox'}
3 outbreak_201 101 {'name': 'Karen', 'disease': 'G-Pox'}
4 outbreak_202 101 {'name': 'Tim', 'disease': 'Z-Pox'}
CodePudding user response:
One way to do this is to convert the json for each outbreak into a dictionary, make a list of all the dictionary key/value pairs and then explode that list and convert the values into the two desired columns:
df['outbreak'] = df['outbreak'].apply(lambda v:json.loads(v).items())
df = df.explode('outbreak')
df[['outbreak_id', 'outbreak_value']] = pd.DataFrame(df.pop('outbreak').tolist(), index=df.index)
Output (for your sample data):
report_id outbreak_id outbreak_value
0 100 outbreak_100 {'name': 'Chris', 'disease': 'A-Pox'}
0 100 outbreak_101 {'name': 'Stacy', 'disease': 'H-Pox'}
1 101 outbreak_200 {'name': 'Brandon', 'disease': 'C-Pox'}
1 101 outbreak_201 {'name': 'Karen', 'disease': 'G-Pox'}
1 101 outbreak_202 {'name': 'Tim', 'disease': 'Z-Pox'}