So I have a spreadsheet which shows product packages and products in it
| Package | Product |
|---|---|
| Package1 | Product1 |
| Package1 | Product2 |
| Package1 | Product3 |
| Package2 | Product1 |
| Package2 | Product3 |
| Package3 | Product2 |
| Package4 | Product1 |
| Package4 | Product2 |
Now I need to backtrace which package was sent to the client given I have a list of products. So if I put somewhere two lines:
| Product1 |
| Product2 |
I need to see result being
- Package4
It could even list all the packages showing a number of matches for a product and how good the match is
| Package # | matches | Exact? |
|---|---|---|
| Package 4 | 2 | EXACT |
| Package 1 | 2 | NOT EXACT |
| Package 2 | 1 | NOT EXACT |
| Package 3 | 1 | NOT EXACT |
I was trying to play with VLOOKUP and INDEX/MATCH but couldn't come up with a good result. Ideally This all should happen on the separate sheet where I can enter my products in some designated cell(s) and get results in another cell(s). There are like 180 packages with with 400 products total
CodePudding user response:
One way would be using the newest functions:
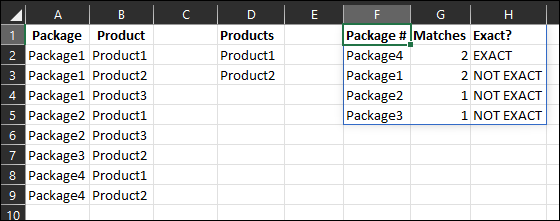
Formula in F1:
=LET(A,UNIQUE(A2:A9),B,D2:D3,C,BYROW(A,LAMBDA(a,SUM(COUNTIFS(A2:A9,a,B2:B9,B)))),D,BYROW(A,LAMBDA(a,SUM(COUNTIF(A2:A9,a)))),E,IF((C=D)*(D=COUNTA(B)),"","NOT ")&"EXACT",VSTACK({"Package #","Matches","Exact?"},SORTBY(HSTACK(A,C,E),E,,C,-1,A,)))
I you don't yet got access to VSTACK() and HSTACK() you can use:
=LET(A,UNIQUE(A2:A9),B,D2:D3,C,BYROW(A,LAMBDA(a,SUM(COUNTIFS(A2:A9,a,B2:B9,B)))),D,BYROW(A,LAMBDA(a,SUM(COUNTIF(A2:A9,a)))),E,IF((C=D)*(D=COUNTA(B)),"","NOT ")&"EXACT",SORTBY(CHOOSE({1,2,3},A,C,E),E,,C,-1,A,))
The downside is that this is now without headers.
CodePudding user response:
A very long shot, but this does the trick in Office365 without Beta formulas or Lambda.
=LET(data,A1:B8,
a,INDEX(data,,1),
b,INDEX(data,,2),
x,C1:C2,
udata,UNIQUE(data),
uda,INDEX(udata,,1),
udb,INDEX(udata,,2),
ua,UNIQUE(a),
cu,MMULT(--(TRANSPOSE(a)=ua),SEQUENCE(ROWS(a),,1,0)),
fuda,FILTER(uda,MMULT(--(TRANSPOSE(x)=udb),SEQUENCE(ROWS(x),,1,0))),
cp,MMULT(--(TRANSPOSE(fuda)=ua),SEQUENCE(ROWS(fuda),,1,0)),
FILTER(ua,(cp=ROWS(x))*(cu=ROWS(x))))
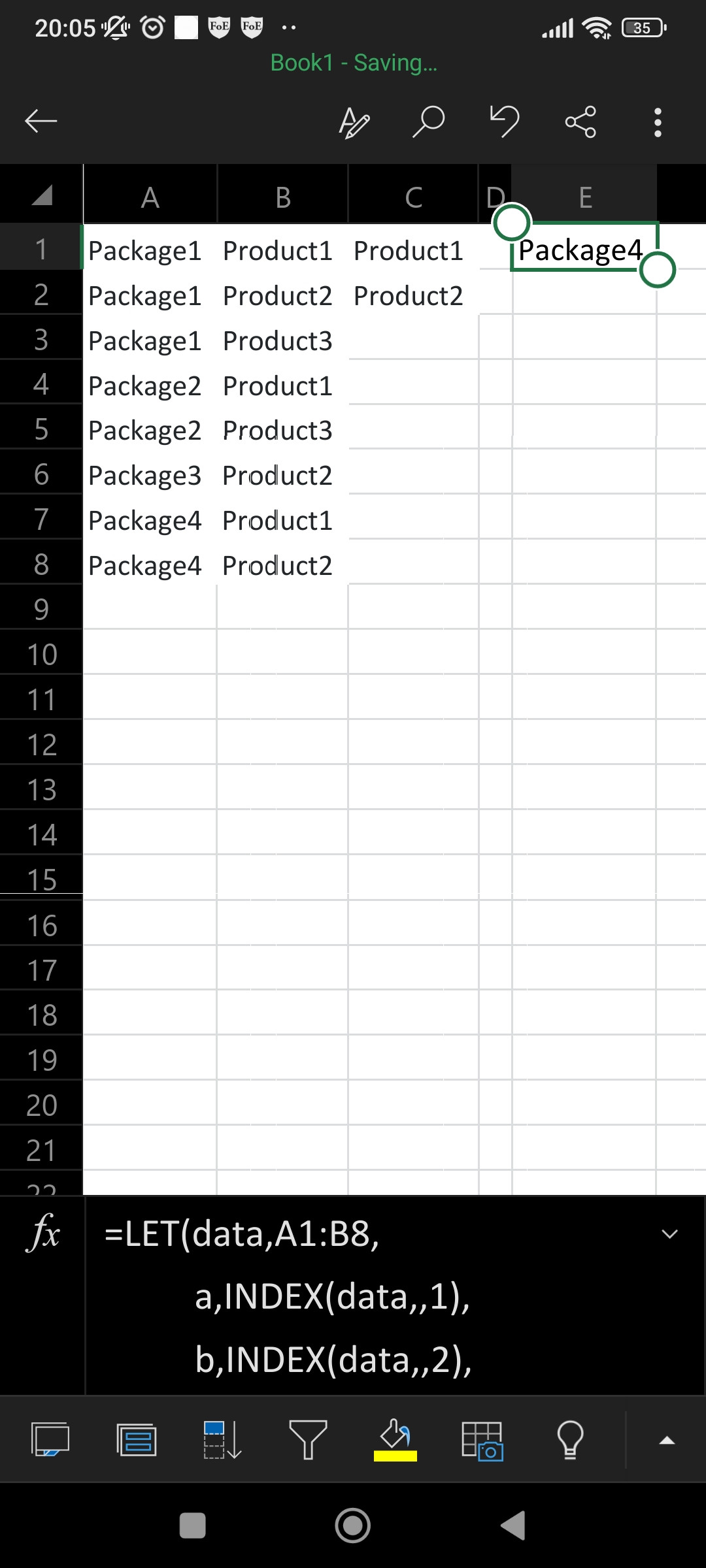
It gets the unique values from column A (ua) and counts the number the unique value appears in column a (cu).
Then - to cope with duplicates giving false count results - I filter the data into unique data (udata).
This is used to filter the first column of this unique data (uda) with a MMULT() of the search values (x) against the unique data column B (udb).
This results in the count of unique values in column A where (unique) column B matches the search values. The counter is called cp.
Finally a filter is set over the unique values of column A where the count of the search values equals the counter cu and equals the counter cp.