I converted an array to a dataframe which has column namesgroupID, ce_acct,bus_nm, res_b2b_prod. I also create a flag variable:
df_corrs=pd.DataFrame(df1a.groupby(['groupID','ce_acct','bus_nm','res_b2b_prod'])['adv','pkg_yld'].corr().unstack().iloc[:,1]).rename(columns={'adv':'correl', 'pkg_yld':''}).reset_index()
def flag(x):
df_corrs.loc[((df_corrs['correl'] >= -1.001) & (df_corrs['correl'] <= -0.51)), 'flag'] = 'a'
df_corrs.loc[((df_corrs['correl'] >= -0.509) & (df_corrs['correl'] <= -0.01)), 'flag'] = 'b'
df_corrs.loc[((df_corrs['correl'] >= 0.00) & (df_corrs['correl'] <= 0.499)), 'flag'] = 'c'
df_corrs.loc[((df_corrs['correl'] >= 0.50) & (df_corrs['correl'] <= 1.001)), 'flag'] = 'd'
df_corrs.loc[(df_corrs['correl'].isnull()), 'flag'] = 'Unknown'
flag(df_corrs['correl'].values)
df_corrs.head(3)
Sample output:
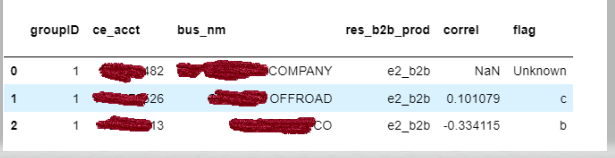
However my column names are in brackets with a comma:
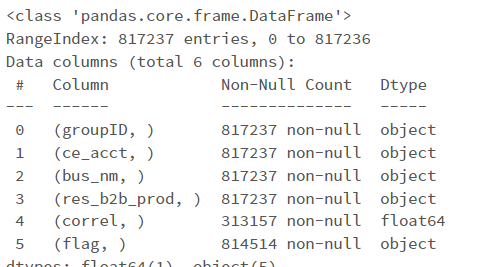
Question: How do I get rid of the round brackets and comma found in each column name?
CodePudding user response:
You can do
df.columns = [
c.replace(', ', '').replace('(', '').replace(')', '')
for c in df.columns
]
CodePudding user response:
This will replace everything and set your columns to the new list
data = {
'{Test_Column,}' : [1, 2, 3, 4, 5],
'(Test_Column1, )':[1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
df.columns = [x.replace('{', '').replace('}','').replace(',', '').replace('(', '').replace(')', '').replace(' ', '') for x in df.columns]
df = df[df.columns]
df