I'm attempting to replace the first section of a value in my dataframe by using a lambda function.
Goal:
- If the Preferred_Name column is not null then replace everything after the "," in Resource_Name with the value listed in Preferred_Name.
- If Preferred_Name is blank ignore the row.
- Once completed, drop the Preferred_Name column.
I wrote this code thus far. I receive an error saying "TypeError: string indices must be integers" which I believe is coming from the loc. function.
df['Resource_Name'] = df['Resource_Name'].apply(
lambda x: x.split()[2] ", " x['Preferred_Name']
if x['Preferred_Name'] == pd.isnull(df.loc[x, 'Preferred_Name'])
else x['Resource_Name']
)
df = df.drop(['Preferred_Name'], axis = 1)
Visual illustration:
Current display:
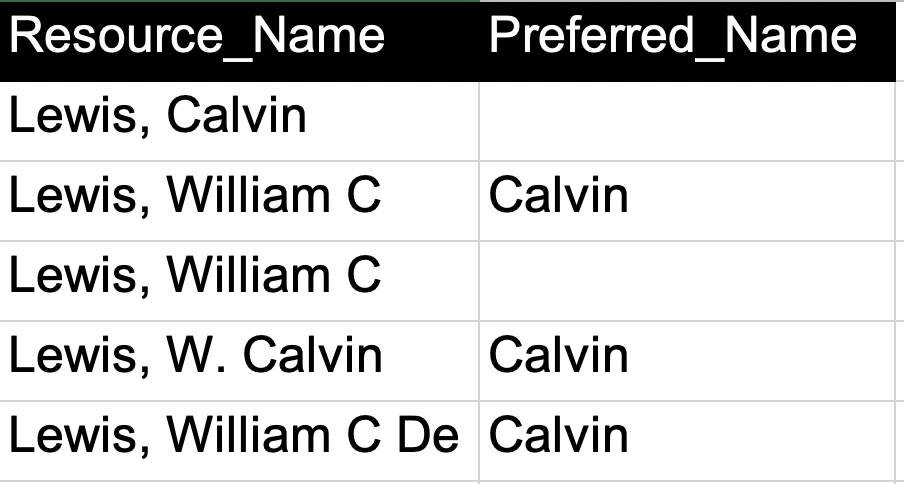
Objective display:
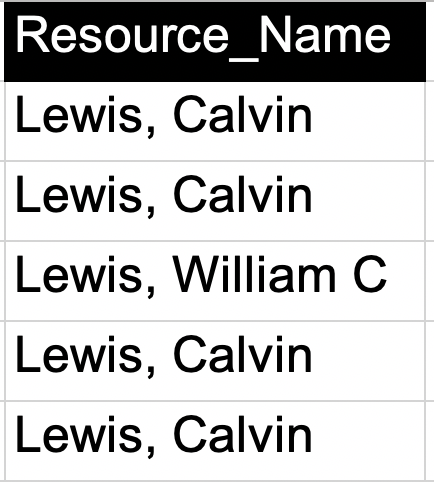
Thank you for your assistance!
CodePudding user response:
You can use .str.split() to split on the comma, take the first part, and then add on the values from Prefered_Name, where Prefered_Name is not an empty string:
new_data = df['Resource_Name'].str.split(r',\s ').str[0] ', ' df['Prefered_Name']
df.loc[df['Prefered_Name'] != '', 'Resource_Name'] = new_data
df = df.drop('Prefered_Name', axis=1)
Output:
>>> df
Resource_name
0 Lewis, Calvin
1 Lewis, Calvin
2 Lewis, William C
3 Lewis, Calvin
4 Lewis, Calvin
CodePudding user response:
This is how I came to the conclusion
import pandas as pd
import numpy as np
data = {
'Resource_Name' : ['Will, Turner C', 'Will, William', 'Will, Williamson', 'Will, Will iam son'],
'Prefered_Name' : [None, 'Bill', None, 'Billy']
}
df = pd.DataFrame(data)
condition_list = [df['Prefered_Name'].values != None]
choice_list = [df['Resource_Name'].apply(lambda x : x.split(',')[0]) ', ' df['Prefered_Name']]
df['Resource_Name'] = np.select(condition_list, choice_list, df['Resource_Name'])
df = df[['Resource_Name']]
df
CodePudding user response:
Here is a solution:
df['Resource_Name'] = df[['Resource_Name', 'Preferred_Name']].apply(
lambda x: f'{x[0].split(",")[0]}, {x[1]}' if x[1] else x[0], axis=1
)
df.drop('Preferred_Name', axis=1, inplace=True)
Output:
>>> df
Resource_Name
0 Lewis, Calvin
1 Lewis, Calvin
2 Lewis, William C
3 Lewis, Calvin
4 Lewis, Calvin
CodePudding user response:
df.loc[~df['Preferred_Name'].isna(), 'Resource_Name'] = \
df[~df['Preferred_Name'].isna()]['Resource_Name'].str.extract('(.*,)').squeeze() ' ' df['Preferred_Name']
df.drop('Preferred_Name', axis=1)
Resource_Name
0 Lewis, Calvin
1 Lewis, Calvin
2 Lewis, William C
3 Lewis, Calvin
4 Lewis, Calvin