I have a data set with values ('ee') of interest by quarter, and multiple fields which indicate the amount of ee in various subsets of the population, as follows:
test=pd.DataFrame(data={'cyq':['2018Q1']*3 ['2018Q2']*3 ['2018Q3']*3 ['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})
I'm trying to get a rolling sum of ee over the quarters, specific to each unique subset of the other fields, in this case species, and group. In my actual data set, I have six identifying fields in total.
The following:
test.groupby(['cyq','species','group']).ee.rolling(window=2).sum()
is producing all NaNs. Other solutions which I've found end up rolling the sum within the each quarter, or only on one identifying field. My goal is to take a rolling sum that recognizes canine a, canine b, and feline a as distinct and rolls their ee values by quarter:
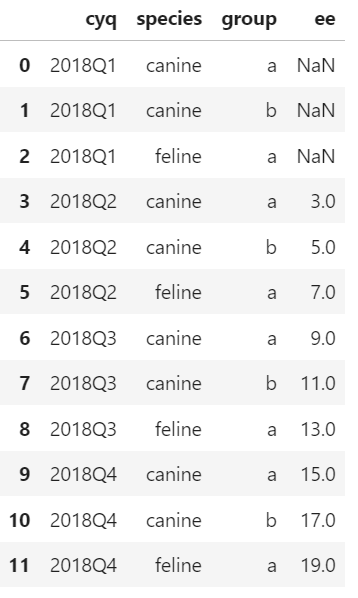
Thank you so much for the help. I feel like there's a simple solution, but variations on this question I've found here aren't working on my dataset.
CodePudding user response:
I don't think you got anything from your first code because there is nothing that would come back based on that grouping. However, I was able to get pretty close to what you were looking for by removing the grouping.
test=pd.DataFrame(data={'cyq':['2018Q1']*3 ['2018Q2']*3 ['2018Q3']*3 ['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})
test['ee'] = test['ee'].rolling(window = 2).sum()
test
CodePudding user response:
You don't get any results because in your provided example after the groupby each group is exactly 1 row. Your rolling window is 2. Look at the documentation for pd.rolling, quote from min_periods.
min_periods : int, default None
Minimum number of observations in window required to have a value; otherwise, result is np.nan. For a window that is specified by an integer, min_periods will default to the size of the window.
Since you never have a window of two all values return NaN. If your real data is bigger and each group has more values, your code will work.
You could set min_periods to 1 so you will get a return value if there is at least one value.