I'm working in Redshift and have two columns from an Adobe Data feed:
post_evar22 and post_page_url.
Each post_evar22 has multiple post_page_url values as they are all the pages that the ID visited. (It's basically a visitor ID and all the pages they visited)
I want to write a query where I can list distinct post_evar22 values that have never been associated with a post_page_url that contains '%thank%' or '%confirm%'.
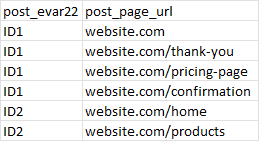
In the dataset below, ID1 would be completely omitted from the query results bceause it was associated with a thank-you page and a confirmation page.
CodePudding user response:
This is a case for NOT EXISTS:
select distinct post_evar22
from table t1
where not exists (
select 1
from table t2
where t2.post_evar22 = t1.post_evar22
and (t2.post_page_url like '%thank%' or t2.post_page_url like '%confirm%')
)
Or MINUS if your dbms supports it:
select post_evar22 from table
minus
select post_evar22 from table where (post_page_url like '%thank%' or post_page_url like '%confirm%')
CodePudding user response:
Seems fairly straight forward. Am I missing something?
SELECT DISTINCT post_evar22
FROM table
WHERE post_page_url NOT LIKE '%thank%'
AND post_page_url NOT LIKE'%confirm%