I am querying some time-series data and would like to apply a query to multiple specified time intervals to get different rows for each interval.
Here is what I mean:
these are the time intervals (don't look at the null one, going to use coalesce()):
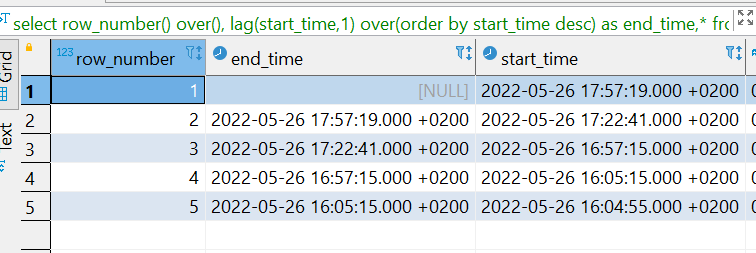
and would like to query my data like this:
select count(*) from time_series where time between [multiple_intervals_here]
the closest I've come to the solution is:
select count(*) from time_series where time (between x and y) or (between a and b)
but obviously, I cannot specify the intervals dynamically and would not get a row for each interval.
(I will apply some more aggregate functions to it, not just count())
The end result would look like this:
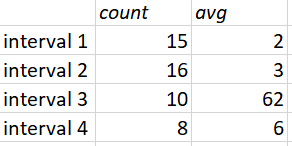
Thanks in advance
CodePudding user response:
Do a separate query for each interval and union the results
select 'interval 1' as interval, count(*) from time_series where time between A and B
union
select 'interval 2' as interval, count(*) from time_series where time between C and D
union
select 'interval 3' as interval, count(*) from time_series where time between E and F
CodePudding user response:
The t CTE is a mimic of the list of intervals.
with t (id, time_start, time_stop) as
(
values
('interval-A', '2022-05-26T10:00'::timestamp, '2022-05-26T12:00'::timestamp),
('interval-B', '2022-05-26T13:00', '2022-05-26T17:00')
)
select t.id, count(l.x) as "count", avg(l.x) as "avg"
from t
cross join lateral
(
select x from the_table tt
where tt.start_time between t.time_start and t.time_stop
and tt.end_time between t.time_start and t.time_stop
) l
group by t.id;