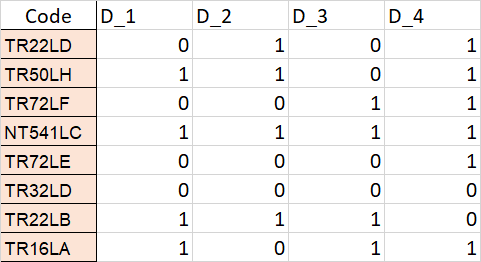
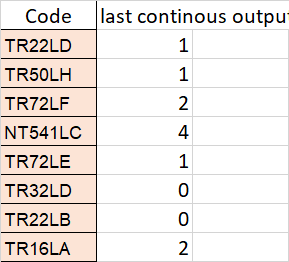
there are 5 column in 1st data frame . by using this find consecutive 1 from last D_4 to D_1, if find 0 in between then break and till that how many ones and that will be output
CodePudding user response:
You can concatenate each row as string from D_4 to D_1, split strings once at first '0' then get the length of the first part:
df['lco'] = (df.iloc[:, :0:-1].astype(str).apply(''.join, axis=1)
.str.split('0', n=1).str[0].str.len())
print(df)
# Output
Code D_1 D_2 D_3 D_4 lco
0 A 0 1 0 1 1
1 B 1 1 0 1 1
2 C 0 0 1 1 2
3 D 1 1 1 1 4
4 E 0 0 0 1 1
5 F 0 0 0 0 0
6 G 1 1 1 0 0
7 H 1 0 1 1 2
CodePudding user response:
You can melt, use a reverse cummin per group to get rid of the trailing 1s, then count the 1s:
df.merge(df.melt('Code', value_name='num')
.groupby('Code')['num']
.apply(lambda s: s[::-1].cummin().sum()),
on='Code'
)
or, in place, with stack:
df['num'] = (df
.iloc[:,1:].stack()
.groupby(level=0)
.apply(lambda s: s[::-1].cummin().sum())
)
output:
Code D_1 D_2 D_3 D_4 num
0 A 0 1 0 1 1
1 B 1 1 0 1 1
2 C 0 0 1 1 2
3 D 1 1 1 1 4
4 E 0 0 0 1 1
5 F 0 0 0 0 0
6 G 1 1 1 0 0
7 H 1 0 1 1 2