I am attempting to master the art of telling python how to partially match values.
Here's the scoop. correct_list is the 'correct' data frame, while list_to_be_audited_partial_matches_ok is the data frame I'd like to ensure is correct. The issue presented here, though, is tricky: The value in list_to_be_audited_partial_matches_ok may or may not be an exact match to the corresponding value in the correct_list, if it's in there at all.
The value in list_to_be_audited_partial_matches_ok may have some sort of extension to the part within the correct_list; the extension could be signaled by a ':' or a "-", for instance.
Here are a few examples of what I need to consider a 'partial match:'
correct_list = {'Item': ["ABCDEF", "FEDCBA", "AA-BB-CCCC", "ABCDEFGH-IJK"]}
correct_list = pd.DataFrame(df1)
correct_list
list_to_be_audited_partial_matches_ok = {'Item': ["ABCDEF", "FEDCBA:XA", "AA-BB-CCCC-01", "AA-BB-CCCC-21:ABC", "ABCDEFGH-IJK-1X"]}
list_to_be_audited_partial_matches_ok = pd.DataFrame(df2)
list_to_be_audited_partial_matches_ok
Here is a picture that color codes the partial matches:

Last bit of request I have is to have a count of all the partial matches listed.
Any ideas on how to partially match these values? Perhaps a new column that displays 'True/False' depending on if there is a partial match or not?
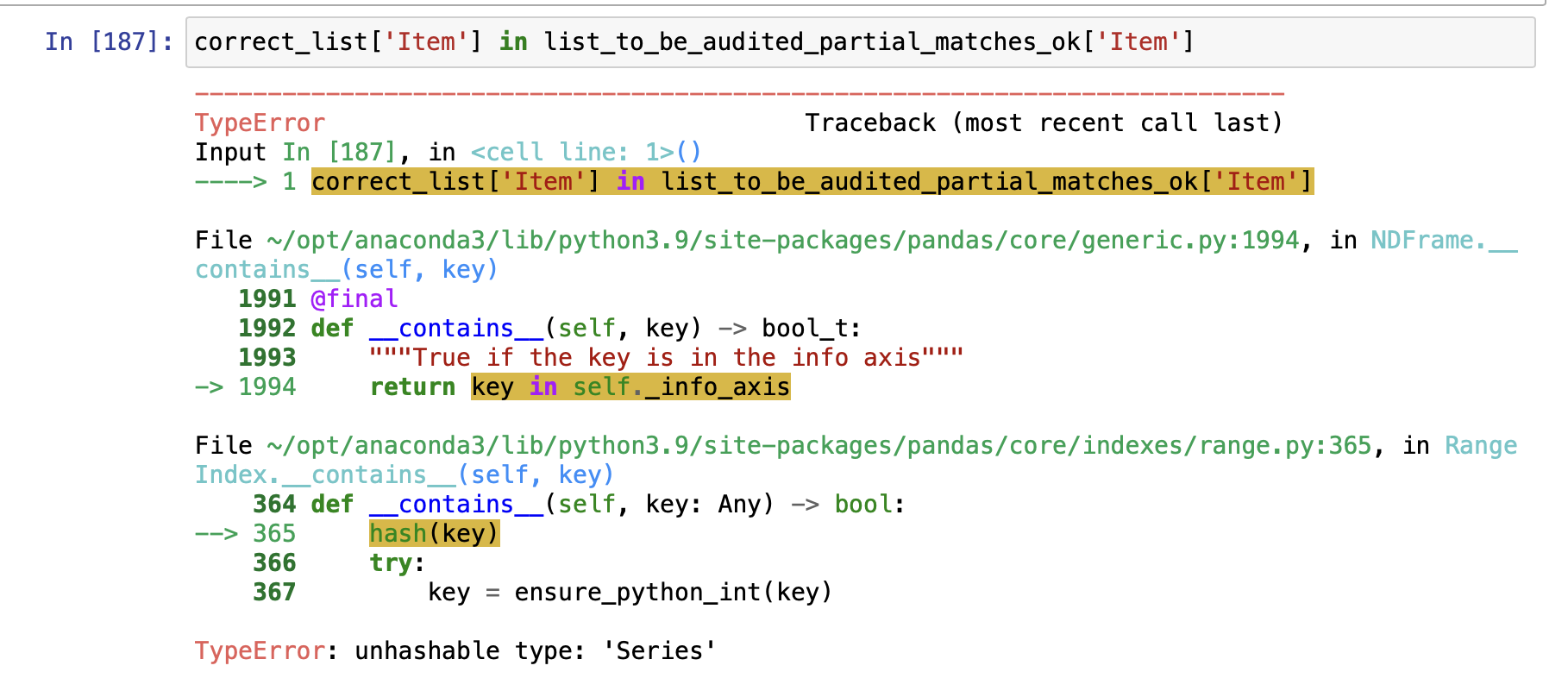
Why wouldn't this work?
Error message I get:
CodePudding user response:
You can remove the part of string from the last - (priority is given to hyphen, since your examples prove the : char can follow the - to remove) till end of string, or from the last : till end of string, and then check if the strings under the audition match any of the strings in the correct list.
import pandas as pd
import re
correct_list = {'Item': ["ABCDEF", "FEDCBA", "AA-BB-CCCC", "ABCDEFGH-IJK"]}
list_to_be_audited_partial_matches_ok = {'Item': ["ABCDEF", "FEDCBA:XA", "AA-BB-CCCC-01", "AA-BB-CCCC-21:ABC", "ABCDEFGH-IJK-1X"]}
df1 = pd.DataFrame.from_dict(correct_list)
df2 = pd.DataFrame.from_dict(list_to_be_audited_partial_matches_ok)
pat = fr'^(?:{"|".join(map(re.escape, df1["Item"]))})$'
df2['Audit Result'] = df2['Item'].str.replace(r'-[^-]*$|:[^:]*$', '', regex=True).str.contains(pat)
Output:
>>> df2
Item Audit Result
0 ABCDEF True
1 FEDCBA:XA True
2 AA-BB-CCCC-01 True
3 AA-BB-CCCC-21:ABC True
4 ABCDEFGH-IJK-1X True
The .str.replace(r'-[^-]*$|:[^:]*$', '', regex=True) part removes the suffixes, see the regex demo. More details:
-[^-]*$--zero or more chars other than-([^-]*) till end of string ($)|:[^:]*$-:zero or more chars other than:([^:]*) till end of string ($).
The .str.contains(pat) checks if the input string fully matches one of the items in df1['Item']. The regex looks like ^(ABCDEF|FEDCBA|AA-BB-CCCC|ABCDEFGH-IJK)$, see its demo.