I'm importing a df and then running hist() on the df:
df <- read.table("https://leicester.figshare.com/ndownloader/files/23581310", sep = ",", header = TRUE, stringsAsFactors = FALSE)
hist(df)
but it doesn't show the histograms of all 124 columns - only a subset. I'm not sure why? How do I get a histogram of all the columns in a df? I want to be able to run hist() on the entire data frame because it also shows the number of values/missing values at the bottom of each histogram.
CodePudding user response:
I wonder how you could at all use hist in a data frame without Vectorizeing it. Best would be you use a different device such as the png.
png('foo.png', 2560, 1440)
par(mfrow=c(12, 11))
Vectorize(hist)(df)
dev.off()

Update
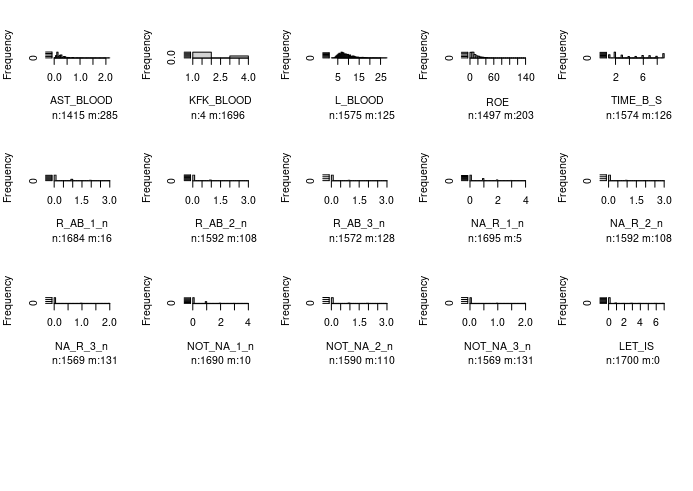
We can get nice titles and labels with nobs and missings using lapply and a misfun for convenience.
misfun <- \(z) paste(
paste(c('n', 'm'), table(factor(as.double(is.na(z)), levels=0:1)), sep=':'),
collapse=' ')
png('foo2.png', 2560, 1440)
par(mfrow=c(12, 11))
lapply(names(df), \(x) hist(df[[x]], main=x, xlab=misfun(df[x])))
dev.off()

Data:
df <- read.table("https://leicester.figshare.com/ndownloader/files/23581310", sep = ",", header = TRUE, stringsAsFactors = FALSE)
CodePudding user response:
If all you are only looking for are the number of missing values in each column but don't really need the histograms, you can do:
colSums(sapply(df, is.na))
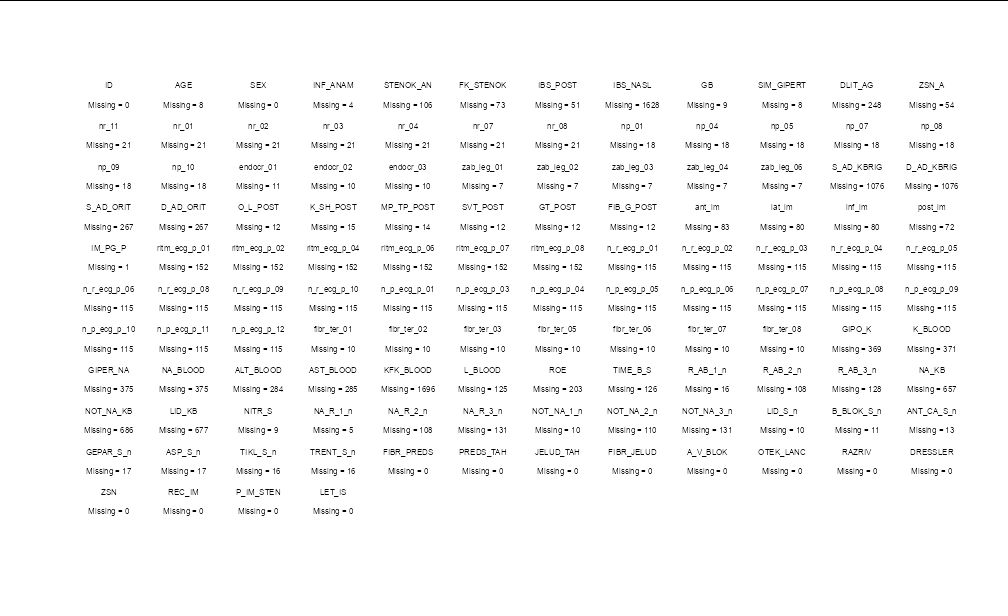
If you need this as an image, then it will be much clearer to draw it with text rather than hist:
df2 <- data.frame(col = paste(names(df), colSums(sapply(df, is.na)),
sep = '\n \nMissing = '),
x = (seq(ncol(df)) - 1) %% 12,
y = 12 - (seq(ncol(df)) - 1) %/% 12)
plot(df2$x, df2$y, type = 'n', xaxt = 'n', yaxt = 'n', xlab = '', ylab = '',
bty = 'n')
text(df2$x, df2$y, label = df2$col, cex = 0.5)