I'm a python newbie and need help with a specfic task. My main goal is to identify all indicies with their specific values and column-names which are greater than 0 within a row and to sum up these values below each other into another column within the same row.
Here is what I tried:
import pandas as pd
import numpy as np
table = {
'A':[0, 2, 0, 5],
'B' :[4, 1, 3, 0],
'C':[2, 9, 0, 6],
'D':[1, 0, 1, 6]
}
df = pd.DataFrame(table)
print(df)
# create a new column that sums up the row
df['summary'] = 'NoData'
# print the header
print(df.columns.values)
A B C D summary
0 0 4 2 1 NoData
1 2 1 9 0 NoData
2 0 3 0 1 NoData
3 5 0 6 6 NoData
# get length of rows and columns
row = len(df.index)
column = len(df.columns)
# If a value at a spefic index is greater
# than 0, take the column name and the value at that index and print it into the column
#'summary'. Also write all values greater than 0 within a row below each other
for i in range(row):
for j in range(column):
if df.iloc[i][j] > 0:
df.at[i,'summary'] = df.columns(df.iloc[i][j]) '\n'
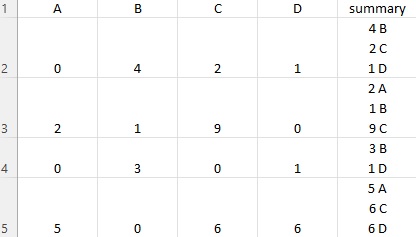
I hope it is a bit clear what I want to achieve. Here is a picture of how the result should look in the column 'summary'
CodePudding user response:
You don't really need a for loop.
Starting with df:
A B C D
0 0 4 2 1
1 2 1 9 0
2 0 3 0 1
3 5 0 6 6
You can do:
# Define an helper function
def f(val, col_name):
# You can modify this function in order to customize the summary string
return "" if val == 0 else str(val) col_name "\n"
# Assign summary column
df["summary"] = df.apply(lambda x: x.apply(f, args=(x.name,))).sum(axis=1).str[:-1]
Output:
A B C D summary
0 0 4 2 1 4B\n2C\n1D
1 2 1 9 0 2A\n1B\n9C
2 0 3 0 1 3B\n1D
3 5 0 6 6 5A\n6C\n6D
It works for longer column names as well:
one two three four summary
0 0 4 2 1 4two\n2three\n1four
1 2 1 9 0 2one\n1two\n9three
2 0 3 0 1 3two\n1four
3 5 0 6 6 5one\n6three\n6four
CodePudding user response:
Try this:
import pandas as pd
import numpy as np
table = {
'A':[0, 2, 0, 5],
'B' :[4, 1, 3, 0],
'C':[2, 9, 0, 6],
'D':[1, 0, 1, 6]
}
df = pd.DataFrame(table)
print(df)
print(f'\n\n-------------BREAK-----------\n\n')
def func(line):
templist = ''
list_col = line.index.values.tolist()
temp = line.values.tolist()
for x in range(0, len(temp)):
if (temp[x] <= 0):
pass
else:
if (x == 0 ):
templist = f"{temp[x]}{list_col[x]}"
else:
templist = f"{templist}\n{temp[x]}{list_col[x]}"
return templist
df['summary'] = df.apply(func, axis = 1)
print(df)
EXIT
A B C D
0 0 4 2 1
1 2 1 9 0
2 0 3 0 1
3 5 0 6 6
-------------BREAK-----------
A B C D summary
0 0 4 2 1 \n4B\n2C\n1D
1 2 1 9 0 2A\n1B\n9C
2 0 3 0 1 \n3B\n1D
3 5 0 6 6 5A\n6C\n6D